

 800+ IT
News
als RSS Feed abonnieren
800+ IT
News
als RSS Feed abonnieren📚 Distributed PCA using TFX
💡 Newskategorie: AI Videos
🔗 Quelle: blog.tensorflow.org
Guest post by Hamza Tahir of maiot, along with Robert Crowe and Tris Warkentin on behalf of the TFX team
Introduction
Principal Component Analysis (PCA) is a dimensionality reduction technique, useful in many different machine learning scenarios. In essence, PCA reduces the dimension of input vectors in a way that retains the maximal variance in your dataset. Reducing the dimensionality of the model input can increase the performance of the model, reduce the size and resources required for training, and decrease non-random noise.TensorFlow Extended (TFX) is a free and open-source platform for creating production-ready, end-to-end machine learning pipelines. At maiot, TFX is an important building block of our Core Engine. Initially built as the foundation of our asset optimization platform, developers can now independently use the Core Engine to manage their own deep learning workloads.
Inside the Engine, we offer many mechanisms for pre-processing data. This includes applying PCA to huge input data for visualization and learning purposes. In light of this, we prepared this post to showcase how to use TFX to apply distributed PCA over a dataset.
TensorFlow Transform
A TFX pipeline consists of components, that in turn leverage a variety of TensorFlow libraries. One of these is TensorFlow Transform: A powerful library used for preprocessing input data for TensorFlow. The output of TensorFlow Transform is exported as a TensorFlow graph, used at both training and serving time. This prevents skew since the same transformations are applied in both stages.Like many of the libraries and components of TFX, TensorFlow Transform performs processing using Apache Beam to distribute workloads on compute clusters. This enables Transform to process very large datasets and to make efficient use of available resources. Apache Beam runs as an abstraction layer on top of widely available distributed computing frameworks, including Apache Spark, Apache Flink, and Google Cloud Dataflow. At maiot, we run Apache Beam on the managed and serverless Cloud Dataflow service, part of the Google Cloud.
With TensorFlow Transform, it is possible to apply PCA as part of your TFX pipeline. PCA is often implemented to run on a single compute node. Thanks to the distributed nature of TFX, it’s now easier than ever to implement a distributed PCA algorithm for scalable processing of large datasets.
Showcase - PCA with TFX
This example colab notebook contains a complete example of running a TFX pipeline with PCA. It utilizes the TFX Interactive Notebook context to create a TFX pipeline that outputs the principal component projection of the widely used Iris dataset.All the magic happens inside the
preprocessing_fn function that gets fed into the Transform component in the TFX pipeline. This function accepts a dictionary of feature tensors and outputs a dictionary of features with applied relevant transformations. While you can use normal TensorFlow code here, many fundamental transformations are already built-in out of the box with TensorFlow Transform (e.g., normalize, bucketize, compute vocabularies, etc.). Find the full list of out-of-the-box transforms here.One of these built-in transforms is the
tft.pca transform, which we will use to compute the PCA of our dataset. Here is how you can utilize this transform in a preprocessing_fn function.def preprocessing_fn(inputs):
features = []
outputs = {}
for feature_tensor in inputs.values():
# standard scaler pre-req for PCA
features.append(tft.scale_to_z_score(feature_tensor))
# concat to make feature matrix for PCA to run over
feature_matrix = tf.concat(features, axis=1)
# get orthonormal vector matrix
orthonormal_vectors = tft.pca(feature_matrix, output_dim=2, dtype=tf.float32)
# multiply matrix by feature matrix to get projected transformation
pca_examples = tf.linalg.matmul(feature_matrix, orthonormal_vectors)
# unstack and add to output dict
pca_examples = tf.unstack(pca_examples, axis=1)
outputs['Principal Component 1'] = pca_examples[0]
outputs['Principal Component 2'] = pca_examples[1]
return outputsThere are a lot of things going on in the above snippet, so let’s take a closer look.
Firstly, we apply a normalization transform to all input tensors. This is important as the PCA algorithm expects that input vector components have been converted to similar units of measurement.
Second, we concatenate our input tensors together to create a feature matrix. Here is where we apply the
tft.pca function. This calculates the orthonormal vector matrix of our data. As explained in the tft.pca documentation, the matrix can be used to calculate the final projection of our data. We do this by multiplying this matrix with the feature matrix. The final step is to ‘unstack’ the projection matrix, separating the individual principal components. We then return these in the output dictionary.When you actually execute a Transform component with the above
preprocessing_fn, a lot goes on under the hood that is abstracted away. To perform distributed processing on a compute cluster TFX creates a distributed Apache Beam pipeline which computes the relevant co-variances and orthonormal vector matrix. It also creates a normal TensorFlow graph with this transformation embedded, which will become part of your trained model, so that you can use the PCA transformation at serving time. The result of PCA is a new vector space with fewer dimensions. At serving time, new data will be projected into that lower dimensional space from the original higher dimensional space.After running a successful TFX pipeline, you can easily use the output of the Transform component to extract the transformed data for visualization. In the accompanying colab, this is exactly what is shown:
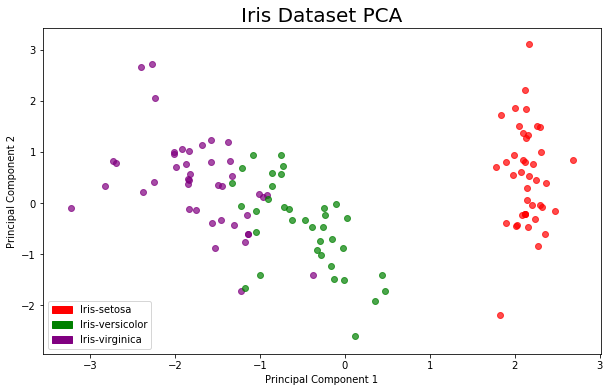
As you can see, the separation between the three classes is clearly visible in the reduced dimension space.