

 800+ IT
News
als RSS Feed abonnieren
800+ IT
News
als RSS Feed abonnieren📚 TensorFlow Lattice: Flexible, controlled and interpretable ML
💡 Newskategorie: AI Videos
🔗 Quelle: blog.tensorflow.org
Posted by Mahdi Milani Fard, Software Engineer, Google Research
Most ML practitioners have encountered the typical scenario where the training data looks very different from the run-time queries on which the model is evaluated. As a result, flexible ML solutions such as DNNs or forests that rely solely on the training dataset often act unexpectedly and even wildly in parts of the input space not covered by the training and validation datasets. This behaviour is especially problematic in cases where important policy or fairness constraints can be violated.
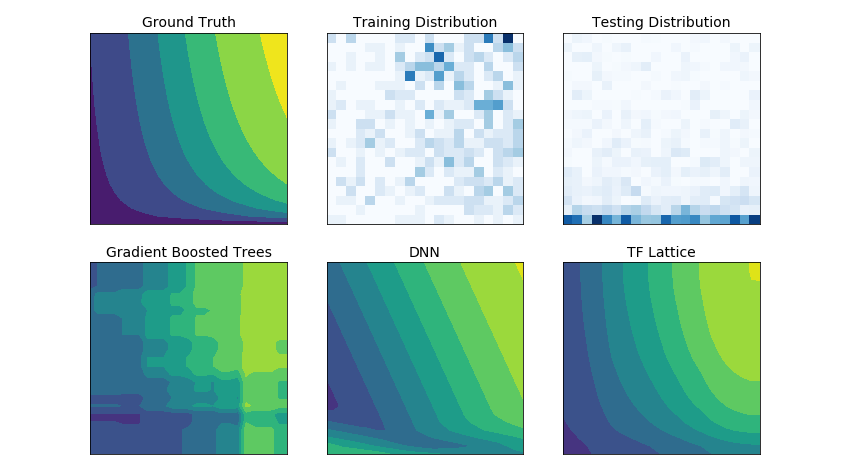 |
| Unconstrained models can behave unexpectedly where there is little training data coverage. Here, DNN and GBT predictions are far from the ground truth on the testing data. |
TF Lattice makes it possible to keep using flexible models, but provides several options to inject domain knowledge into the learning process through semantically meaningful common-sense or policy-driven shape constraints. For example, you can specify that the model output should be monotonically increasing with respect to a given input. These extra pieces of domain knowledge can help the model learn beyond just the training dataset and makes it behave in a manner controlled and expected by the user.
TensorFlow Lattice Library
TensorFlow Lattice is a library for training constrained and interpretable lattice based models. A lattice is an interpolated look-up table that can approximate arbitrary input-output relationships in your data.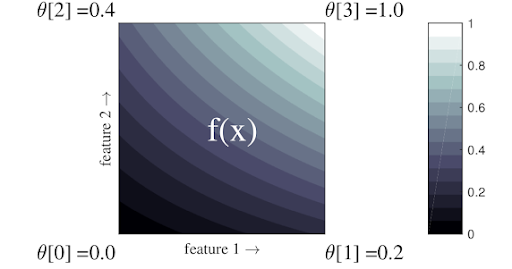
TensorFlow Lattice also provides piecewise linear functions (with tfl.layers.PWLCalibration Keras layer) to calibrate and normalize the input features to the range accepted by the lattice: 0 to 1 in the example lattice above.
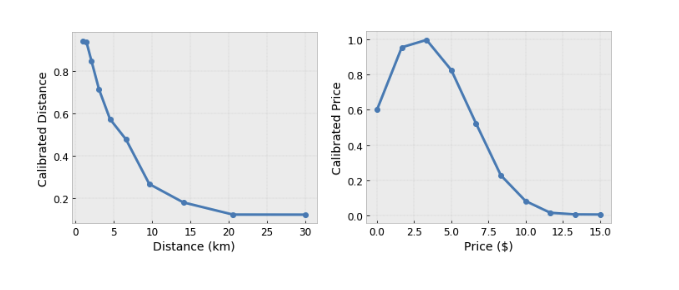
There are several forms of constraints you can impose on TensorFlow Lattice layers to inject your knowledge of the problem domain into the training process:
- Monotonicity: You can specify that the output should only increase/decrease with respect to an input. In our example, you may want to specify that increased distance to a coffee shop should only decrease the predicted user preference.
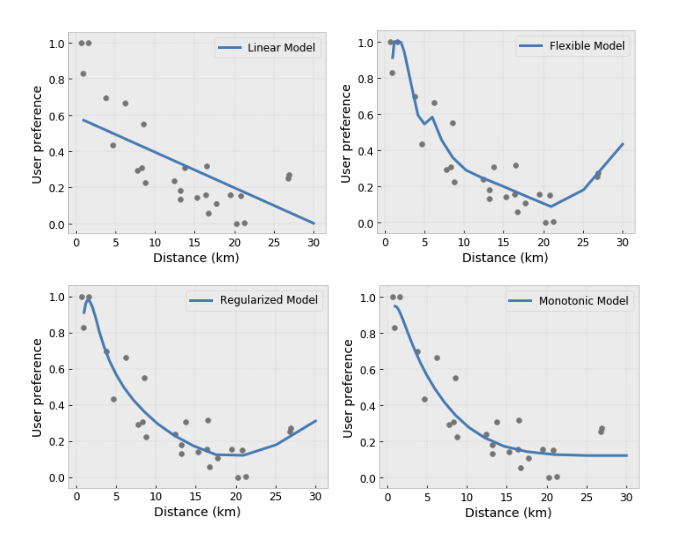
- Convexity/Concavity: You can specify that the function shape can be convex or concave. Mixed with monotonicity, this can force the function to represent diminishing returns with respect to a given feature.
- Unimodality: You can specify that the function should have a unique peak or unique valley. This lets you represent functions that are expected to have a sweet spot with respect to a feature.
- Pairwise trust: This constraint suggests that one input feature semantically reflects trust in another feature. For example, a higher number of reviews makes you more confident in the average star rating of a restaurant. The model will be more sensitive with respect to the star rating (i.e. will have a larger slope with respect to the rating) when the number of reviews is higher.
- Pairwise dominance: This constraint suggests that the model should treat one feature as more important than another feature. This is done by making sure the slope of the function is larger with respect to the dominant feature.
Example: Ranking Restaurants
This example is from our end-to-end shape constraint tutorial that covers many of the above mentioned constraints with canned estimators. Imagine a scenario where we want to determine whether or not users will click on a restaurant search result. The task is to predict the clickthrough rate (CTR) given input features:- average rating: a numeric feature in the range 1 to 5
- number of reviews: a numeric feature in range 0 to 200
- sollar rating: a categorical feature with values “$” to “$$$$” represented as 0 to 3 and missing value represented as -1
- Output is monotonically increasing in average rating
- Output is monotonically increasing in number of reviews, but with diminishing returns
- The model should trust the average rating more when there are more reviews
- Users typically prefer “$$” restaurants to “$” restaurants
model = tf.keras.models.Sequential()
model.add(
tfl.layers.ParallelCombination([
# Feature: average rating
tfl.layers.PWLCalibration(
# Input keypoints for the piecewise linear function
input_keypoints=np.linspace(1., 5., num=20),
# Output is monotonically increasing in this feature
monotonicity='increasing',
# This layer is feeding into a lattice with 2 vertices
output_min=0.0,
output_max=1.0),
# Feature: number of reviews
tfl.layers.PWLCalibration(
input_keypoints=np.linspace(0., 200., num=20),
# Output is monotonically increasing in this feature
monotonicity='increasing',
# There is diminishing returns on the number of reviews
convexity='concave',
# Regularizers defined as a tuple ('name', l1, l2)
kernel_regularizer=('wrinkle', 0.0, 1.0),
# This layer is feeding into a lattice with 3 vertices
output_min=0.0,
output_max=2.0),
# Feature: dollar rating
tfl.layers.CategoricalCalibration(
# 4 rating categories + 1 missing category
num_buckets=5,
default_input_value=-1,
# Partial monotonicity: calib(0) monotonicities=[(0, 1)],
# This layer is feeding into a lattice with 2 vertices
output_min=0.0,
output_max=1.0),
]))
model.add(
tfl.layers.Lattice(
# A 2x3x2 grid lattice
lattice_size=[2, 3, 2],
# Output is monotonic in all inputs
monotonicities=['increasing', 'increasing', 'increasing']
# Trust: more responsive to input 0 if input 1 increases
edgeworth_trusts=(0, 1, 'positive')))
model.compile(...)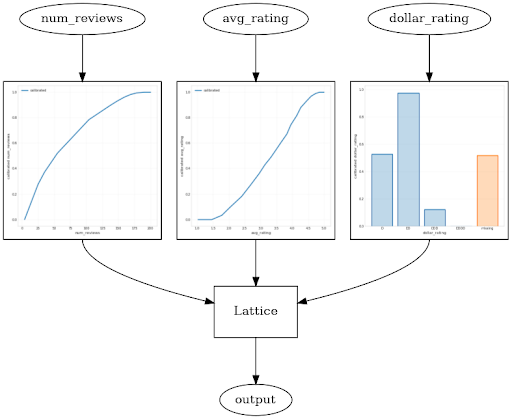
Feedback
We are looking forward to hearing your thoughts and comments on the library. For bugs or issues, please reach out to us on Github.Acknowledgements
This release was made possible with contributions from Oleksandr Mangylov, Mahdi Milani Fard, Taman Narayan, Yichen Zhou, Nobu Morioka, William Bakst, Harikrishna Narasimhan, Andrew Cotter and Maya Gupta.Publications
For further details on the models and algorithms used within the library, check out our publications on lattice models:- Deontological Ethics By Monotonicity Shape Constraints, Serena Wang, Maya Gupta, International Conference on Artificial Intelligence and Statistics (AISTATS), 2020
- Shape Constraints for Set Functions, Andrew Cotter, Maya Gupta, H. Jiang, Erez Louidor, Jim Muller, Taman Narayan, Serena Wang, Tao Zhu. International Conference on Machine Learning (ICML), 2019
- Diminishing Returns Shape Constraints for Interpretability and Regularization, Maya Gupta, Dara Bahri, Andrew Cotter, Kevin Canini, Advances in Neural Information Processing Systems (NeurIPS), 2018
- Deep Lattice Networks and Partial Monotonic Functions, Seungil You, Kevin Canini, David Ding, Jan Pfeifer, Maya R. Gupta, Advances in Neural Information Processing Systems (NeurIPS), 2017
- Fast and Flexible Monotonic Functions with Ensembles of Lattices, Mahdi Milani Fard, Kevin Canini, Andrew Cotter, Jan Pfeifer, Maya Gupta, Advances in Neural Information Processing Systems (NeurIPS), 2016
- Monotonic Calibrated Interpolated Look-Up Tables, Maya Gupta, Andrew Cotter, Jan Pfeifer, Konstantin Voevodski, Kevin Canini, Alexander Mangylov, Wojciech Moczydlowski, Alexander van Esbroeck, Journal of Machine Learning Research (JMLR), 2016
- Optimized Regression for Efficient Function Evaluation, Eric Garcia, Raman Arora, Maya R. Gupta, IEEE Transactions on Image Processing, 2012
- Lattice Regression, Eric Garcia, Maya Gupta, Advances in Neural Information Processing Systems (NeurIPS), 2009