

 800+ IT
News
als RSS Feed abonnieren
800+ IT
News
als RSS Feed abonnieren📚 Even Faster Mobile GPU Inference with OpenCL
💡 Newskategorie: AI Videos
🔗 Quelle: blog.tensorflow.org
Posted by Juhyun Lee and Raman Sarokin, Software Engineers
While the TensorFlow Lite (TFLite) GPU team continuously improves the existing OpenGL-based mobile GPU inference engine, we also keep investigating other technologies. One of those experiments turned out quite successful, and we are excited to announce the official launch of OpenCL-based mobile GPU inference engine for Android, which offers up to ~2x speedup over our existing OpenGL backend, on reasonably sized neural networks that have enough workload for the GPU.
 |
| Figure 1. Duo's AR effects are powered by our OpenCL backend. |
Improvements over the OpenGL Backend
Historically, OpenGL is an API designed for rendering vector graphics. Compute shaders were added with OpenGL ES 3.1, but its backward compatible API design decisions were limiting us from reaching the full potential of the GPU. OpenCL, on the other hand, was designed for computation with various accelerators from the beginning and is thus more relevant to our domain of mobile GPU inference. Therefore, we have looked into an OpenCL-based inference engine, and it brings quite a lot of features that let us optimize our mobile GPU inference engine.Performance Profiling: Optimizing the OpenCL backend was much easier than OpenGL, because OpenCL offers good profiling features and Adreno supports them well. With these profiling APIs, we are able to measure the performance of each kernel dispatch very precisely.
Optimized Workgroup Sizes: We have observed that the performance of TFLite GPU on Qualcomm Adreno GPUs is very sensitive to workgroup sizes; picking the right workgroup size can boost the performance, whereby picking the wrong one can degrade the performance by an equal amount. Unfortunately, picking the right workgroup size is not trivial for complex kernels with complicated memory access patterns. With the help of the aforementioned performance profiling features in OpenCL, we were able to implement an optimizer for workgroup sizes, which resulted in up to 50% speedup over the average.
Native 16-bit Precision Floating Point (FP16): OpenCL supports FP16 natively and requires the accelerator to specify the data type's availability. Being a part of the official spec, even some of the older GPUs, e.g. Adreno 305 from 2012, can operate at their full capabilities. OpenGL, on the other hand, relies on hints which the vendors can choose to ignore in their implementations, leading to no performance guarantees.
Constant Memory: OpenCL has a concept of constant memory. Qualcomm added a physical memory that has properties that makes it ideal to be used with OpenCL's constant memory. This turned out to be very efficient for certain special cases, e.g. very thin layers at the beginning or at the end of the neural network. OpenCL on Adreno is able to greatly outperform OpenGL's performance by having a synergy with this physical constant memory and the aforementioned native FP16 support.
Performance Evaluation
Below, we show the performance of TFLite on the CPU (single-threaded on a big core), on the GPU using our existing OpenGL backend, and on the GPU using our new OpenCL backend. Figure 2 and Figure 3 depict the performance of the inference engine on select Android devices with OpenCL on a couple of well-known neural networks, MNASNet 1.3 and SSD MobileNet v3 (large), respectively. Each group of 3 bars are to be observed independently which shows the relative speedup among the TFLite backends on a device. Our new OpenCL backend is roughly twice as fast as the OpenGL backend, but does particularly better on Adreno devices (annotated with SD), as we have tuned the workgroup sizes with Adreno's performance profilers mentioned earlier. Also, the difference between Figure 2 and Figure 3 visualizes that OpenCL performs even better on larger networks. |
| Figure 2. Inference latency of MNASNet 1.3 on select Android devices with OpenCL. |
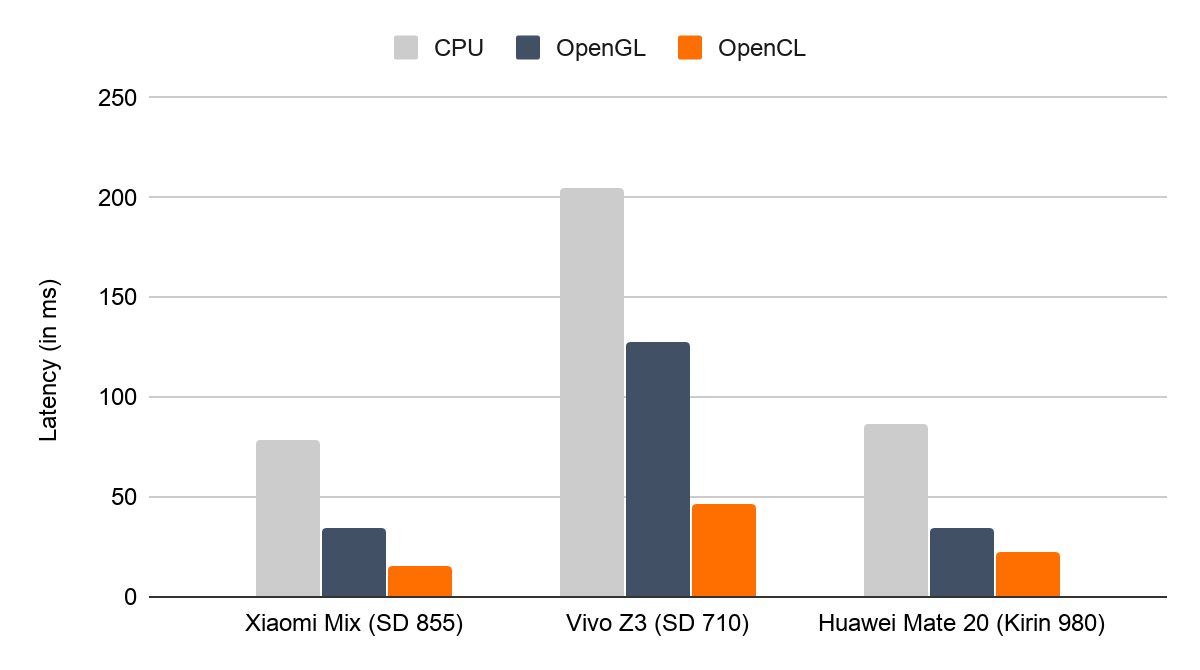 |
| Figure 3. Inference latency of SSD MobileNet v3 (large) on select Android devices with OpenCL. |
Seamless Integration through the GPU Delegate
One major hurdle in employing the OpenCL inference engine is that OpenCL is not a part of the standard Android distribution. While major Android vendors include OpenCL as part of their system library, it is possible that OpenCL is not available for some users. For these devices, one needs to fall back to the OpenGL backend which is available on every Android device.To make developers' life easy, we have added a couple of modifications to the TFLite GPU delegate. We first check the availability of OpenCL at runtime. If it is available, we employ the new OpenCL backend as it is much faster than the OpenGL backend; if it is unavailable or couldn't be loaded, we fall back to the existing OpenGL backend. In fact, the OpenCL backend has been in the TensorFlow repository since mid 2019 and seamlessly integrated through the TFLite GPU delegate v2, so you might be already using it through the delegate's fallback mechanism.
Acknowledgements
Andrei Kulik, Matthias Grundman, Jared Duke, Sarah Sirajuddin, and special thanks to Sachin Joglekar for his contributions to this blog post....