

 800+ IT
News
als RSS Feed abonnieren
800+ IT
News
als RSS Feed abonnieren📚 Why Training Your Own Transformer Language Model from Scratch is (not) Stupid
💡 Newskategorie: AI Nachrichten
🔗 Quelle: towardsdatascience.com
When does pre-training your own Transformer language model make sense?
What are the pitfalls, benefits, and steps of pre-training your own model, and the limitations of existing PLMs?

Who is this blog post for and what to expect from this blog post?
The goal of this blog post is to talk about how Pre-trained Language Models (PLM) can be used in creating Natural Language Processing (NLP) products and what the upsides and downsides are of using them. Training your own Transformer model from scratch will be discussed. High-level benefits and pitfalls of pre-training from scratch are presented. The content is intended for new and experienced NLP engineers but also for other professionals involved in creating products that involve NLP.
What are pre-trained Transformer language models and why are they so popular?
PLMs are large models that are pre-trained on large amounts of data, using self-supervised pre-training tasks. Transformer models are a specific type of PLM that are based on the self-attention mechanism as introduced in [0]. There are many variants of Transformer models and many can be found on Hugging Face (HF) [1]. HF is an open-source platform, where industrial and academic researchers can upload and download models. The training of these huge models from scratch is usually done by very large companies such as Google, Facebook, and OpenAI or research institutes such as the Allen Institute for AI. With the rise of Hugging Face many engineers that would not have the resources or knowledge to create such a model have gotten access to use them. Taking a PLM and applying it to new problems is a form of transfer learning.
BERT [2] is one of the most famous PLMs among NLP practitioners and was released in 2018. For the majority of people, however, GPT-3 [3] is likely the most well-known model. Both models are based on the Transformer architecture [0]. Open-source Transformer models have become ubiquitous in NLP products and research. With just a few lines of code, using the transformers library [1] developed by HF, it is possible to apply a pre-trained Transformer model to your new task.
At Slimmer AI, an AI venture studio, we (co-)build ventures in areas we believe AI can be disruptive. While building ventures is a big part of what we do, we also support the scientific publishing processes by applying our AI expertise. For these products, we are constantly looking for ways to improve performance. We experiment with pre-trained Transformer models to see if they are a good fit for a product. However, we do not always have room to experiment with or try out something completely new within a project due to delivery deadlines. For this reason, Slimmer AI introduced the AI Fellowship, in which ML engineers take time to sharpen their skills and learn about the latest developments. This allows us to dive deeper into topics than we would for our day-to-day jobs of building products. Read more about our AI Fellowship here. Training your own Transformer language model from scratch is a large project and not something we would do while building an individual product. In the AI Fellowship, we explored and experimented with training our own language model.
After reading this blog post you will gain an understanding of:
- What pre-trained Transformer models are and where to find them, more specifically, you will learn about BERT [2] and SciBERT [4].
- In what ways a pre-trained model has domain knowledge and what you could do to adapt a model to your domain.
- Why applying these models is constrained by the limitations of these models and what their limitations are.
- How you could overcome these limitations without pre-training your own model.
- What the benefits are of pre-training your own model from scratch.
- What you should take into account when (considering) training your own Transformer based language model.
Why PLMs are not magic bullets: a SciBERT case study
When considering Transformer PLMs, there are two main things that we, as ML engineers, look for:
1) the architecture of the model: the number of layers, parameters, attention mechanism, pre-train tasks, etc.
2) the domain of the data used to train the model.
As an applied ML engineer, one of the key skills is to identify the problem and domain that you are working on. If you correctly identify the problem, you can effectively search and apply the most relevant tools that you can find. For example, if you are working on legal data, applying a model trained on English legal texts is more likely going to give you better results than a model trained on general English Wikipedia.
In that line of thought, BERT is a general model because it is not trained on a specific data domain. It is trained on general English text from the BookCorpus dataset and the English Wikipedia. SciBERT [4], on the other hand, is a specialized model that is trained on scientific papers from the Semantic Scholar corpus. It is therefore a logical choice to apply this model to all the products you create for the scientific publishing industry. Problem solved right? Not exactly ….
SciBERT, released in 2019, is a powerful model that is tailored to the scientific domain with amazing capabilities and it is still a powerful model today. There are other models out there that are also specialized in scientific domains such as BioBERT [5] or SPECTER [6], but in this blog post, we will stick to discussing SciBERT [4]. The main drawbacks to using SciBERT [4] while building products in the scientific publishing industry are:
- Speed. It needs a GPU to be fast, which can be costly.
- Performance. Its performance is not always that much better than some of the more lightweight models. This is why for every product you develop you need to have a more simple baseline such as Word2Vec [8] embeddings and see if your PLM significantly outperforms it.
- Input restrictions. The maximum sequence length it can handle is 512 tokens.
- Domain. While SciBERT is a model trained on academic papers, the domains of these papers are not very diverse. About 80% of the training data consists of papers from the biomedical domain and the remaining 20% from the computer science domain. There are many different scientific disciplines out there not covered by this corpus.
🐌 SciBERT speed and input restrictions
The most lightweight way to make use of a PLM, like SciBERT, is to use it in a frozen manner. This entails loading the model and using the model with the weights as they are on the checkpoint as opposed to fine-tuning the model by altering the weights to your task. You only need to forward pass your corpus to create document embeddings (representations). Large PLMs like SciBERT are complex models with many parameters. It is crucial that the task performance increases with the complexity of the model. We will look at the speed in this section and performance in the next section.
We can use Hugging Face benchmarks to get some concrete examples of how long it takes SciBERT to featurize texts. We take a batch size of 256 and abstract lengths of 128, 256, and 512 WordPieces [7].
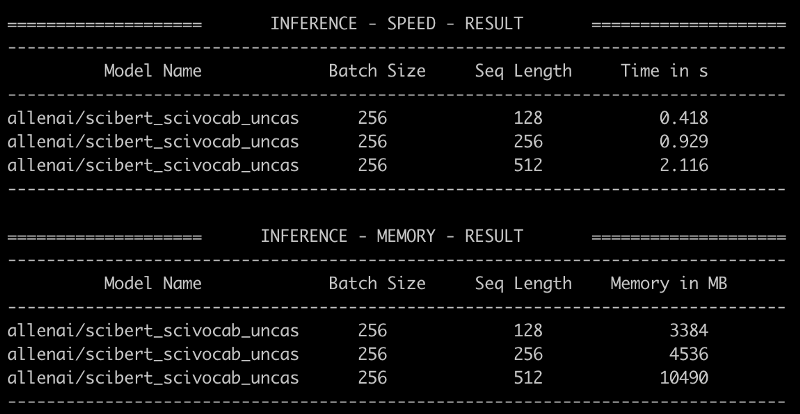
Figure 1 — SciBERT benchmarking via Hugging Face on an NVIDIA GeForce RTX 2080 Ti. Image by the author.
Suppose you have a corpus of four million papers and you use around 512 WordPieces per paper (e.g., the title and abstract). Then, given our benchmark above we would require 55 minutes of processing time:
featurize_time_in_minutes = ((4_000_000 / 256) * 2.116) / 60
print(featurize_time_in_minutes)
55.104166666666664
This is still a manageable amount of time and we can store our embedding vectors and load the papers every time we want to do a new experiment. This requires some IO management but is not a definite blocker for experimentation.
However, 512 tokens aren’t always enough. This amount roughly translates to the size of a paper abstract. For some use cases, it’s preferred to use (part of) the full text. In this scenario, the text needs to be chunked in batches of 512, because SciBERT can only handle 512 WordPieces as a maximal input. Let’s say, on average, these papers contain 5120 WordPieces (which is conservative). This means that for each paper you need 10 batches of 512. Which would make our featurize step almost 10 hours long.
Moreover, in production, it’s preferred to be able to run the model on a CPU instance, as GPU instances are more expensive. When ML products are moved to production the models are stored in a container and depending on the infrastructure of the organization they are either self-hosted or hosted through a cloud provider. When models are self-hosted the organization itself is responsible for managing the hardware where the model will run. Using a cloud provider abstracts this away and an organization pays for the time it uses the cloud provider’s hardware. The better the hardware the more expensive it gets. Having a GPU instance is much more expensive than having a CPU instance. This is what the costs look like on the Google Cloud Platform (GCP) assuming the endpoint is running 24/7.
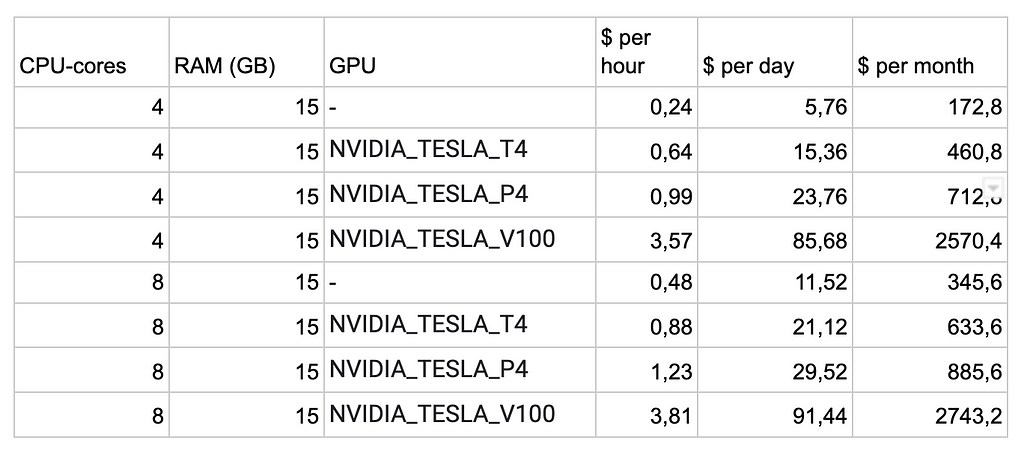
The image above shows a stark difference in costs. A CPU inference container is much cheaper.
In the section above we looked at benchmarking on GPU, now let us move to CPU, how long would it take to featurize on a CPU using SciBERT? Let’s take batches of 1, 16, and 32 this time. As larger batches take too long.
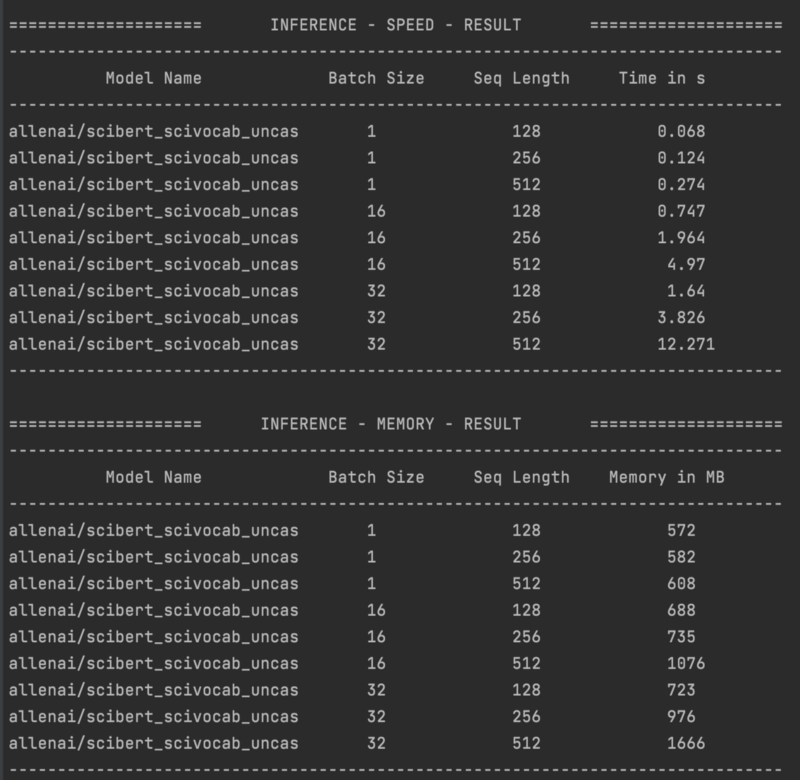
Figure 2 — SciBERT benchmarking on laptop CPU (Intel i7). Image by Author.
In Figure 2, we see some of the limitations. It is not very feasible to run this on a CPU, especially when using (part of) the full text. It takes 12.271 seconds to featurize a batch of 32 by 512, if we again assume longer docs to be about 5120 WordPieces we would have to wait over 2 minutes to just get the embeddings. This quickly becomes a bottleneck in production.
Model domains
As introduced before, SciBERT is a model tailored for the scientific domain, but what exactly is the scientific domain? Let us dive a little deeper. The concept of domain in NLP is vaguely defined and often used in an intuitive way [10]. Within the same language, there are vast differences in terms of style, vocabulary, topic, and other linguistic nuances. It is common and typical in NLP to speak, for example, of data from the ‘medical domain’. However, which texts fit into this domain is not clearly defined. In [11] the authors take text from different sources such as medical text, legal text, and IT texts (software manuals). Through clustering experiments with different large PLMs, they show that it is not trivial to distinguish between these three sources.
PLMs are increasing in size and one could wonder if a big enough model even merits being adapted to a more niche domain. In [12] the authors show that for a big model like RoBERTa [13] it still merits adapting the model to a specific domain. They test the model’s performance in the biomedical and computer science domain before and after domain adaptation. For both domains, the model’s performance improves after adaptation.
We can say that there are two ways a model is tailored to a domain:
- Through the weights of the model’s network.
- Through the vocabulary of the model.
What is the role of the weights of the model?
The weights encode all knowledge in a model. When text is given as input to the model a numerical representation of that text is created based on the weight matrices of the model.
What is vocabulary?
Traditionally, a model’s vocabulary would consist of all the unique words that occur in the training data. This is not scaleable. In the case of BERT and SciBERT, the models make use of subword tokenization, more specifically WordPiece tokenization [7]. As a result, the vocabulary consists of small pieces of a word or subwords. Different models use different algorithms for their tokenization, and hence yield a different vocabulary, but in general, the subwords are created based on their frequency of occurring in the corpus used to train the model.
The main benefit of using subwords is that the model can deal with out-of-vocabulary words, words that haven’t been seen during training. The role of a model’s vocabulary is a relatively under-researched aspect of Transformer models. In [14], the authors train a language model using the RoBERTA objective for two languages, English and Japanese, and show that using different vocabulary construction methods impact performance. At their time of writing, they wrote that a model’s vocabulary cannot be altered after training and is thus a critical decision in a model’s architecture. In [15] a method for altering a method’s vocabulary is introduced but this is not widely implemented. A model’s vocabulary is still a critical component.
Let us take a look at some of the vocabulary differences between BERT and SciBERT to better understand how having a different vocabulary impacts the tokenization of domain-specific words. We will look at four scientific terms: ‘antilipopolysaccharides’, ‘angiography’, ‘brachytherapy’, and ‘electroencephalography’. It is typical of the scientific domain to have these longer domain-specific words in them.
antilipopolysaccharides
BERT tokenizer: [‘anti’, ‘##lip’, ‘##op’, ‘##ol’, ‘##ys’, ‘##ac’, ‘##cha’, ‘##ride’, ‘##s’]
SciBERT tokenizer: [‘anti’, ‘##lip’, ‘##opolysaccharide’, ‘##s’]
angiography
BERT tokenizer: [‘ang’, ‘##iography’]
SciBERT tokenizer: [‘angiography’]
brachytherapy
BERT tokenizer: [‘bra’, ‘##chy’, ‘##therapy’]
SciBERT tokenizer: [‘brachy’, ‘##therapy’]
electroencephalography
BERT tokenizer: [‘electro’, ‘##ence’, ‘##pha’, ‘##log’, ‘##raphy’]
SciBERT tokenizer: [‘electroencephal’, ‘##ography’]
‘##’ indicates that it is a new WP belonging to the preceding word.
In the first example of the word ‘antilipopolysaccharides’ we see a big difference between the SciBERT and BERT tokenizers. The SciBERT tokenizer breaks the word up into 4 WordPieces while the BERT tokenizer breaks the word up into 9 WordPieces. The difference between the models is that the SciBERT model has ‘opolysaccharide’ as part of its vocabulary.
In the second example, the complete word ‘angiography’ is part of SciBERT’s model vocabulary. If we want to get a single vector to give a numerical representation of the word ‘angiography’ we have to take the average, or any other weighting measure, in the case of BERT. However, if we use SciBERT we do not have to average between WordPieces. This is beneficial because the model can encode specialized knowledge in such unique tokens, as opposed to spreading the knowledge over multiple tokens which are also used in other words. An additional benefit of this specialized vocabulary is that the sequence length becomes shorter and thus faster to compute, or it allows for taking in more context when dealing with a larger text.
To pre-train or not to pre-train?
In the previous sections, we established some limitations of a model like SciBERT and why it is not ideal for us. In this section, we will look at the pros and cons of the alternatives. Our problem is that there is no pre-trained model available on Hugging Face that meets our requirements:
- Fast and efficient inference: preferably no GPU to save costs. Low latency and low memory.
- State-of-the-art (SOTA) or near-SOTA performance on a diverse set of scientific texts.
- Be able to handle sequences longer than 512 tokens.
Designing and training your own model is a lot of work and even though we have tools and frameworks to assist us, it is not a trivial task. When working in applied AI, training a model from scratch is quite a drastic and costly measure.
In broad strokes, there are two things that we can do if we want to have a pre-trained Transformer model to help us solve our problems:
- Pre-train a model from scratch.
- Alter an existing model. This can be done through techniques such as compression, knowledge distillation [18], and fine-tuning.
Let us take a look at these techniques, what control they give over the model and how
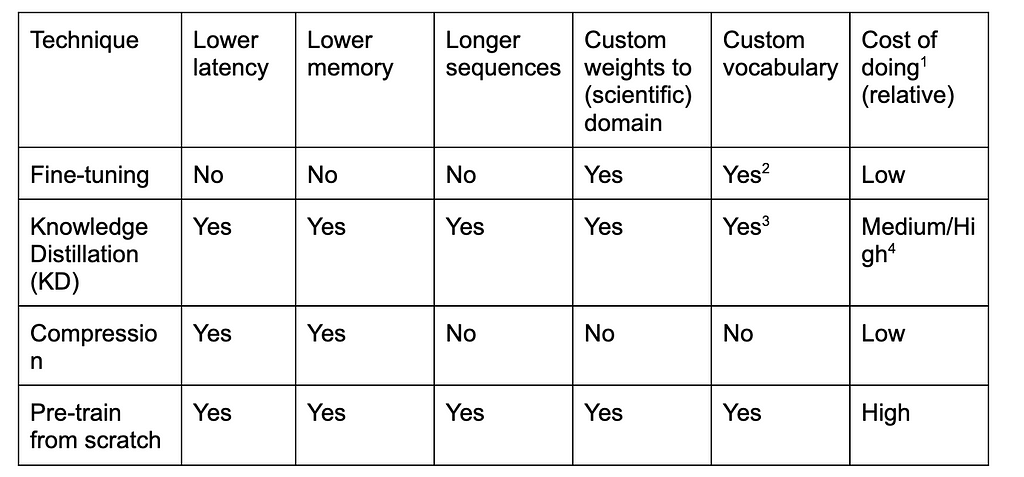
Some notes on the information presented in the table:
- The costs are in terms of both time and money if you are using cloud GPUs.
- In the established fine-tuning pipeline vocabulary adaptation is not customary, in [15] the authors show a way to do this but this is not an established practice. Usually, in fine-tuning only, the weights are adapted.
- In [16] they show a method of how to use KD from a model with a large vocabulary and move to a model with a smaller vocabulary.
- The cost of KD is dependent on the choices you make. Bigger student network, higher costs $$$, and longer training.
(There are different compression techniques that can be used, but discussing how they work is beyond the scope of this blog post. Knowledge distillation can be seen as a compression technique and in this post, we listed it separately because it is operationally different from other compression techniques. In distillation, a new (smaller) model based on the knowledge of a (bigger) teacher model is trained. This is different from other compression techniques such as pruning [17], where connections from an existing model are removed. In distillation, there is a lot more freedom and thus a lot more choices to make. For example, the architecture of the distilled model can be very different from the teacher model.
For fine-tuning, there is some bad news. Even though on Hugging Face we can find a lot of models freely available, there are not many models available that would fit the needs described above. There are three models on Hugging Face that fulfills at least one of our requirements: being able to handle longer sequences than SciBERT:
- allenai/longformer-base-4096
- google/bigbird-roberta-base
- uw-madison/nystromformer
But these do not fulfill all of our requirements, the reason why these models are able to handle longer sequences than BERT is that they use a different attention mechanism. For a detailed overview of the different attention mechanisms used in different PLMs, have a look at this post by Thomas van Dongen.
If we look at the table above we see that both distillation and pre-training from scratch score a ‘yes’ on all columns. However, even for distillation, it is technically possible to alter the vocabulary, fine-tune weights for a new domain, implement a new attention mechanism, and lower the latency all at the same time, this can become messy quite quickly. Just as SciBERT is not a magic bullet there is also no quick win in terms of alternative models or techniques.
What to expect when you’re pre-training?
Pre-training a model from scratch is a large project with benefits and potential pitfalls. In this section, we will look at those and list the steps you need to take to train your own model.
What are the benefits of training your own model?
- You get a deeper understanding of the techniques you are using and gain experience with data and architecture optimization. This is something you don’t have to deal with when fine-tuning models.
- Fully customized to your preferences. Everything is exactly how you want it. And therefore likely to give you the custom performance you need.
- It looks cool and you get to think of a name for your model.
After reading these benefits you might be excited and ready to start your pre-training but before you do that, take a look at these pitfalls.
Pitfalls of pre-training your own model.
- Decisions: There are a lot of decisions to take. E.g., architecture (depth, type of layers, type of attention, etc), loss function(s), training algorithms, datasets, and hyperparameters.
- Large project: This is not your regular side project and it’s difficult to manage next to a full-time job. Because of the large amount of work involved it is not something that can be done on your own and there will be interdependencies.
- Compute power: There is a lot of training and experimentation needed. To do this, you need to have access to adequate computing power. Which comes with costs. Even if you have access to multiple GPUs you need to make sure that you are using them efficiently.
- Prove you’re better: If you want to publish your model and results you have to prove you are better on a range of evaluation tasks. This is not trivial to achieve because you need to make sure all of your testing conditions are the same for the models you are trying to beat.
Now you understand the benefits and pitfalls and if you decided to pre-train your own model from scratch, here are the steps you need to take.
Steps to pre-train your own Transformer model.
- Data. Decide which data you are going to use, inspect it and pay particular attention to your sequence lengths. Do you have mostly long sequence text or mostly short sequence texts?
- Tokenizer. Decide which tokenization method you are going to use and what will be the size of your vocabulary.
- Attention. Decide which attention mechanism you are going to use, this will decide how long your sequence length can be. Many mechanisms are implemented in the Xformers library.
- Objectives. Decide what pre-training objective(s) you are going to use. If you want to keep your training efficient you need to look for efficient pre-training tasks such as ELECTRA [19].
- Train. Start training. In this phase, you will optimize your hyperparameters.
- Evaluate. Evaluate your model. Depending on your objective, if you are planning to only use your model for your own products/solutions you do not have to evaluate your model on a broad set of academic tasks but can evaluate your model directly on those tasks.
- Optimize. Optimize your model. Even if you already made efficient architecture choices it is worth looking into optimization (e.g., ONNX, distillation, pruning) to achieve lower latency.
- Deploy. Incorporate it into your products and measure if there is a real-life impact.
Closing remarks
If your goal is to quickly develop a good product you do not need to pre-train your own custom language model. It is possible to move fast and create a product quickly by using a PLM. It might not be an optimal solution but in some cases, it might be good enough. It is particularly important to validate whether your imported PLM adds enough value to justify its size and speed.
Pre-training your own model is an investment both in terms of time as in terms of computing power. If you’re successful in training a model, you’ve got something you can use for your future products. Moreover, if it is allowed, depending on your privacy and data rights, you can publish your model and other people can make use of it. We make use of open-source code and models every day and being able to contribute to it is a good way of saying “thank you”.
References
[0] Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., & Brew, J. (2019). HuggingFace’s Transformers: State-of-the-art Natural Language Processing. ArXiv, abs/1910.03771.
[1] Vaswani, A., Shazeer, N.M., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., & Polosukhin, I. (2017). Attention is All you Need. ArXiv, abs/1706.03762.
[2] Devlin, J., Chang, M., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. ArXiv, abs/1810.04805.
[3] Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T.J., Child, R., Ramesh, A., Ziegler, D.M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., & Amodei, D. (2020). Language Models are Few-Shot Learners. ArXiv, abs/2005.14165.
[4] Beltagy, I., Lo, K., & Cohan, A. (2019). SciBERT: A Pretrained Language Model for Scientific Text. Conference on Empirical Methods in Natural Language Processing.
[5] Lee, J., Yoon, W., Kim, S., Kim, D., Kim, S., So, C.H., & Kang, J. (2020). BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36, 1234–1240.
[6] Cohan, A., Feldman, S., Beltagy, I., Downey, D., & Weld, D.S. (2020). SPECTER: Document-level Representation Learning using Citation-informed Transformers. Annual Meeting of the Association for Computational Linguistics.
[7] Schuster, M., & Nakajima, K. (2012). Japanese and Korean voice search. 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 5149–5152.
[8] Mikolov, T., Chen, K., Corrado, G.S., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. International Conference on Learning Representations.
[9] Lo, K., Wang, L.L., Neumann, M., Kinney, R.M., & Weld, D.S. (2020). S2ORC: The Semantic Scholar Open Research Corpus. Annual Meeting of the Association for Computational Linguistics.
[10] Wees, M.V., Bisazza, A., Weerkamp, W., & Monz, C. (2015). What’s in a Domain? Analyzing Genre and Topic Differences in Statistical Machine Translation. ACL.
[11] Aharoni, R., & Goldberg, Y. (2020). Unsupervised Domain Clusters in Pretrained Language Models. Annual Meeting of the Association for Computational Linguistics.
[12] Gururangan, S., Marasović, A., Swayamdipta, S., Lo, K., Beltagy, I., Downey, D., & Smith, N.A. (2020). Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks. ArXiv, abs/2004.10964.
[13] Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., & Stoyanov, V. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. ArXiv, abs/1907.11692.
[14] Bostrom, K., & Durrett, G. (2020). Byte Pair Encoding is Suboptimal for Language Model Pretraining. Findings.
[15] Samenko, I., Tikhonov, A., Kozlovskii, B.M., & Yamshchikov, I.P. (2021). Fine-Tuning Transformers: Vocabulary Transfer. ArXiv, abs/2112.14569.
[16] Kolesnikova, A., Kuratov, Y., Konovalov, V., & Burtsev, M.S. (2022). Knowledge Distillation of Russian Language Models with Reduction of Vocabulary. ArXiv, abs/2205.02340.
[17] LeCun, Y., Denker, J.S., & Solla, S.A. (1989). Optimal Brain Damage. NIPS.
[18] Hinton, G.E., Vinyals, O., & Dean, J. (2015). Distilling the Knowledge in a Neural Network. ArXiv, abs/1503.02531.
[19] Clark, K., Luong, M., Le, Q.V., & Manning, C.D. (2020). ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. ArXiv, abs/2003.10555.
Why Training Your Own Transformer Language Model from Scratch is (not) Stupid was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
...