

 800+ IT
News
als RSS Feed abonnieren
800+ IT
News
als RSS Feed abonnieren📚 The 5 Stages of Machine Learning Validation
💡 Newskategorie: AI Nachrichten
🔗 Quelle: towardsdatascience.com
Ensure high-quality machine learning across the ML lifecycle

Introduction
Machine learning has been booming in recent years. It is becoming more and more integrated into our everyday lives, and is providing a huge amount of value to businesses across industries. PWC predicts AI will contribute $15.7 trillion to the global economy by 2030. It sounds too good to be true…
However, with such a large potential value-add to the global economy and society, why are we hearing stories of AI going catastrophically wrong so frequently? And from some of the largest, most technologically advanced businesses out there.
I’m sure you have seen the headlines, including both Amazon and Apple’s gender biased recruiting tool and credit card offerings, which not only impacted their respective company reputation, but could’ve had a massive negative impact on society as a whole. Additionally, the famous iBuying algorithm from Zillow, that due to unpredictable market events led the company to reduce the value of their real-estate portfolio by $500m.
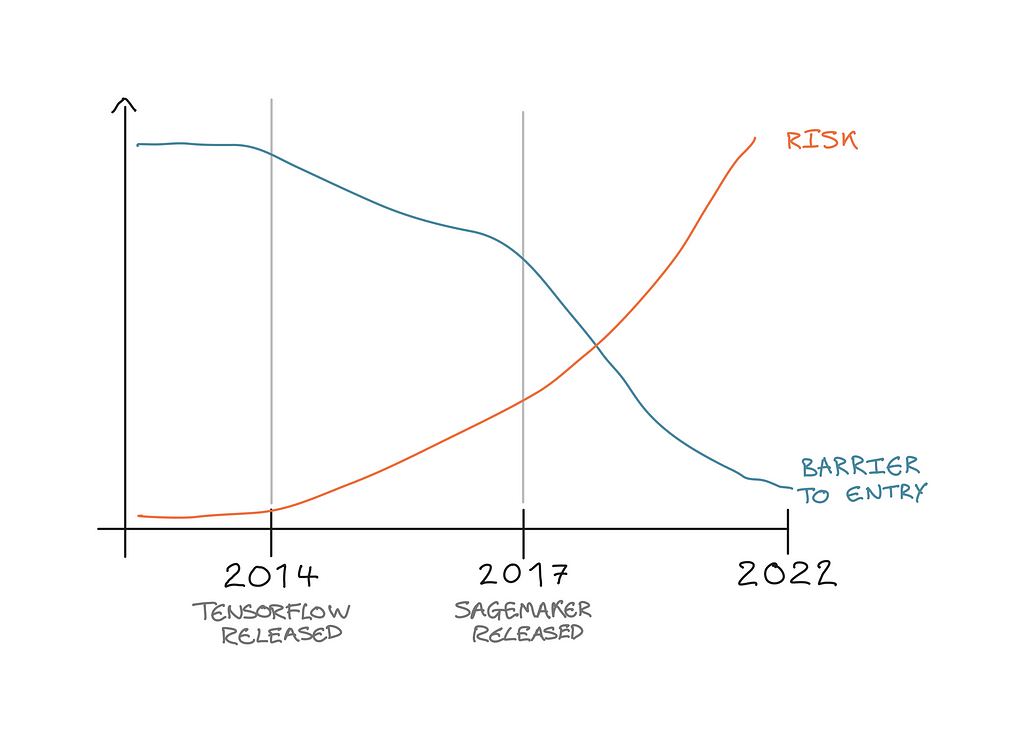
Going back 8 years or so, before tools such as Tensorflow, PyTorch, and XGBoost, the main focus in the Data Science world was how to actually build and train a machine learning model. Following the creation of the tools listed above, and many more, Data Scientists were able to put their theory into practice and began to build machine learning models to solve real-world problems.
After the model building phase was solved, a lot of the focus in recent years has been to start generating real-world value, by getting models into production. A lot of the large end-to-end platforms such as Sagemaker, Databricks and Kubeflow have done a great job providing flexible and scalable infrastructure for deploying machine learning models to be consumed by the wider business and/or general public.
Now the tools and infrastructure are available to effectively build and deploy machine learning, the barrier for businesses to make machine learning available to external customers, or used to make business decisions has been massively reduced. Therefore, the risk of stories like the above happening more frequently, becomes greater and greater.
That’s where machine learning validation comes in…
Contents
- Introduction
- What is machine learning validation?
- The 5 stages of machine learning validation
- ML data validations
- Training validations
- Pre-deployment validations
- Post-deployment validations
- Governance & compliance validations - Benefits of having an ML validation policy
TL;DR
- Machine learning systems cannot be tested with traditional software testing techniques.
- Machine learning validation is the process of assessing the quality of the machine learning system.
- 5 different types of machine learning validations have been identified:
- ML data validations: to assess the quality of the ML data
- Training validations: to assess models trained with different data or parameters
- Pre-deployment validations: final quality measures before deployment
- Post-deployment validations: ongoing performance assessment in production
- Governance & compliance validations: to meet government and organisational requirements - Implementing a machine learning validation process will ensure ML systems are built with high quality, are compliant, and accepted by the business to increase adoption.
What is machine learning validation?
Due to the probabilistic nature of machine learning, it is difficult to test machine learning systems the same way as traditional software (i.e. with unit tests, integration testing etc.). As the data and environment around a model frequently changes over time, it is not good practice to just test a model for specific outcomes. As a model showcasing a correct set of validations today, may be very wrong tomorrow.
Additionally, if an error is identified in the model or data, the solution cannot be to just simply implement a fix. Again, this is due to the changing environments around a machine learning model and the need to retrain. If the solution is only a model fix, then the next time the model is retrained, or the data is updated, the fix will be lost and no longer accounted for. Therefore, model validations should be implemented to check for certain model behaviours and data quality.
It is important to note, when we talk about validation here, we are not referring to the typical validation performed in the training stage of the machine learning lifecycle. What we mean by machine learning validation is the process of testing a machine learning system to validate the quality of the system outside the means of traditional software testing. Tests should be put in place across all stages of the machine learning lifecycle, to validate both the machine learning system quality before it is launched into production. As well as continuously monitoring the systems health in production to detect any potential deterioration.
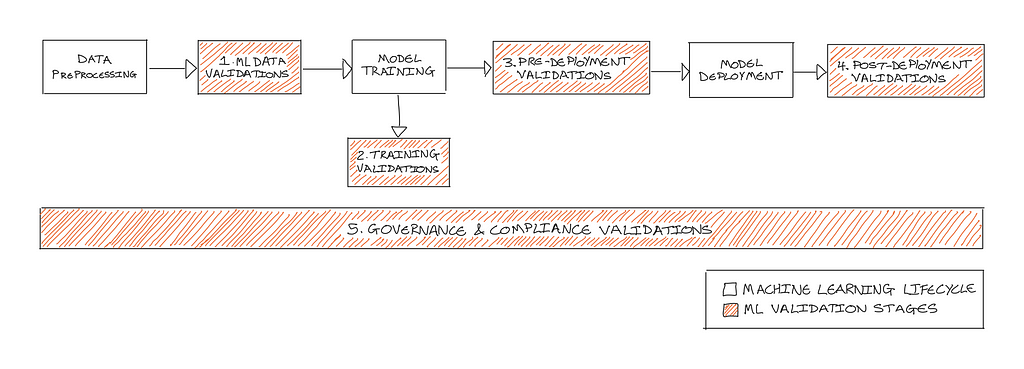
The 5 stages of machine learning validation
As shown below in Figure 2, 5 key stages of machine learning validation have been identified:
- ML Data validations
- Training validations
- Pre-deployment validations
- Post-deployment validations
- Governance & compliance validations
The remainder of this article will break down each stage further to outline, what it is, types of validations and examples for each category.
1. ML data validations
Recently, there has been a large shift towards data-centric machine learning development. This has highlighted the importance of training a machine learning model with high-quality data. A machine learning model learns to predict a certain outcome based on the data it was trained on. So, if the training data is a poor representation of the target state, the model will give a poor prediction. To put it simply, garbage in, garbage out.
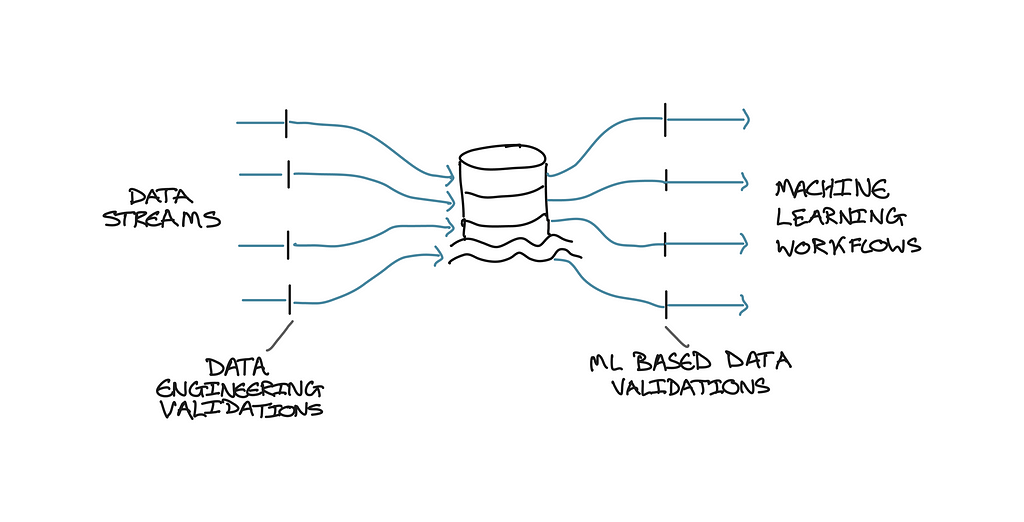
Data validations assess the quality of the dataset being used to train and test your model. This can be broken down into two subcategories:
- Data Engineering validations — Identify any general issues within the data set, based on basic understanding and rules. This might include checking for null columns and NAN values throughout the data, as well as known ranges. For example, confirming the data for a feature of “Age” should be between 0–100.
- ML-based data validations — Assess the quality of the data for training a machine learning model. For example, ensuring the dataset is evenly distributed so the model won’t be biased or have a far greater performance for a certain feature or value.
As shown in Figure 3, below, it is best practice for the Data Engineering validations to be completed prior to your machine learning pipeline. Therefore, only the ML-based data validations should be performed within the machine learning pipeline itself.
2. Training validations
Training validations involve any validation where the model needs to be retrained. Typically, this includes testing different models during a single training job. These validations are performed in the training/evaluation stage of the model’s development, and are often kept as experimentation code that doesn’t make the final cut to production.
A few examples of how training validations are used in practice include:
Hyperparameter optimisation — Techniques to find the best set of hyperparameters (e.g. Grid Search) are often used, but not validated. Comparing performance of a model that has gone through a hyperparameter optimization with performance of a model containing a fixed set of hyperparameters is a simple validation. Complexity can be added to this process by testing the effect of tweaking a single hyper param has an expected outcome on model performance.
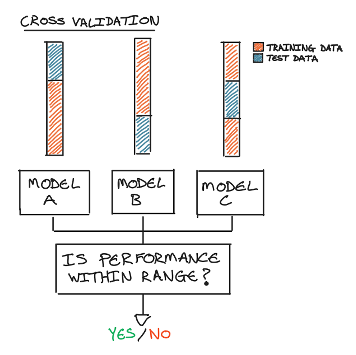
Cross-validation — Running training on different splits of the data can be translated into validations, for example validating that the performance output of each model is within a given range, ensuring that the model generalises well.
Feature selection validations — Understanding how important or influential certain features are should also be a continuous process throughout the model’s lifecycle. Examples include removing features from the training set or adding random noise features, to validate the impact this has on metrics such as performance/feature importance.
3. Pre-deployment validations
After model training is complete and a model is selected, the final model’s performance and behaviour should be validated outside of the training validation process. This involves creating actionable tests around measurable metrics. For example, this might include reconfirming the performance metrics are above a certain threshold.
When assessing the performance of a model, it is common practice to look at metrics such as accuracy, precision, recall, F1 score or a custom evaluation metric. However, we can take this a step further by assessing these metrics across different data slices throughout a data set. For example, for a simple house price regression model, how does the model’s performance compare when predicting the house price of a 2 bedroom property and a 5 bedroom property. This information is rarely shared with users of the model, but can be greatly informative to understand a model’s strengths and weaknesses, thus contributing to growing trust of the model.

Additional performance validations may also include, comparing the model to a random baseline model, to ensure the model is actually fitting to the data; or testing that the model inference time is below a certain threshold, when developing a low latency use case.
Other validations outside of performance can also be included. For example, the robustness of a model should be validated by checking single edge cases, or that the model accurately predicts on a minimum set of data. Additionally, explainability metrics can also be translated into validations, for example to check if a feature is within the top N most important features.
It is important to reiterate that all of these pre-deployment validations take a measurable metric and build it into a pass/fail test. The validations act as a final “go / no go” before the model is used in production. Therefore, these validations act as a preventative measure to ensure that a high quality and transparent model is about to be used to make the business decisions it was built for.
4. Post-deployment validations (model monitoring)
Once the model has passed the pre-deployment stage, it is promoted into production. As the model is then making live decisions, post-deployment validations are used to continuously check the health of the model, to confirm it is still fit for production. Therefore, post-deployment validations act as a reactive measure.
As a machine learning model predicts an outcome based on the historical data it has been trained on, even a small change in the environment around the model can result in dramatically incorrect predictions. Model monitoring has become a widely adopted practice within the industry to calculate live model metrics. This might include rolling performance metrics, or a comparison of the distribution of the live and training data.
Similar to pre-deployment validations, post-deployment validation is the practice of taking these model monitoring metrics and turning them into actionable tests. Typically, this involves alerting. For example, if the live accuracy metric drops below a certain threshold, an alert is sent, triggering some sort of action, such as a notification to the Data Science team, or an API call to start a retraining pipeline.
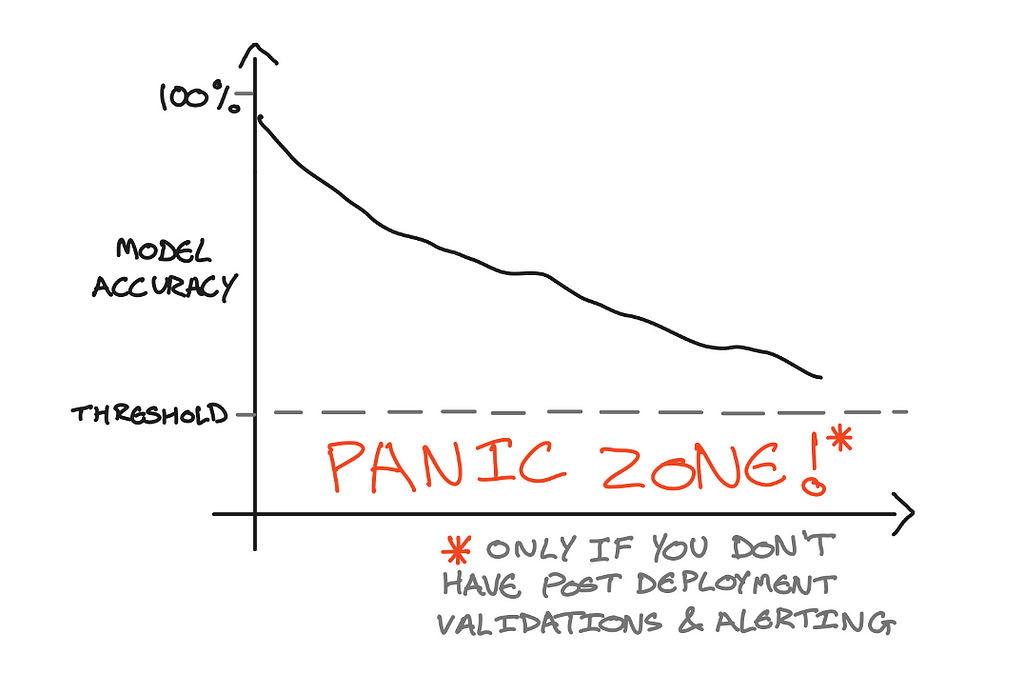
Post-deployment validations include:
- Rolling performance calculations — If the machine learning system has the ability to gather feedback if the prediction was correct or not, performance metrics can be calculated on the fly. The live performance can then be compared to the training performance, to ensure they are within a certain threshold and not declining.
- Outlier detection — By taking the distribution of the model’s training data, anomalies can be detected on real-time requests. By understanding if a data point is within a certain range of the training data distribution. Going back to our Age example, if a new request contained “Age=105”, this would be flagged as an outlier, as it is outside of the distribution of the training data (which we previously defined as ranging from 0–100).
- Drift detection — To identify when the environment around a model has changed. A common technique used is to compare the distribution of the live data to the distribution of the training data, and checking it is within a certain threshold. Using the “Age” example again, if the live data inputs suddenly started receiving a large number of requests with Age>100, the distribution of the live data would change, and have a higher median than the training data. If this difference is greater than a certain threshold drift would be identified.
A/B testing — Before promoting a new model version into production, or to find the best performing model on live data, A/B testing can be used. A/B testing sends a subset of traffic to model A, and a different subset of traffic to model B. By assessing the performance for each model with a chosen performance metric, the higher performing model can be selected and promoted to production.
5. Governance & compliance validations
Having a model up and running in production, and making sure it is generating high quality predictions is important. However, it is just as important (if not more) to ensure that the model is making predictions in a fair and compliant manner. This includes meeting regulations set out by governing bodies, as well as aligning to specific company values of your organisation.
As discussed in the introduction, recent news articles have shown some of the world’s largest organisations getting this very wrong, and introducing biased / discriminating machine learning models into the real-world.
Regulations such as GDPR, EU Artificial Intelligence Act and GxP are beginning to put policies in place to ensure organisations are using machine learning in a safe and fair manner.
These policies include things such as:
- Understanding and identifying the risk of an AI-system (broken down into unacceptable risk, high risk and limited & minimal risk)
- Ensuring PII data is not stored or used inappropriately
- Ensuring protected features such as gender, race or religion are not used
- Confirming the freshness of the data a model is trained on
- Confirming a model is frequently retrained and up to date, and there are sufficient retraining processes in place
An organisation should define their own AI/ML compliance policy that aligns with these official government AI/ML compliance acts and their company values. This will ensure organisations have the necessary processes and safeguards in place when developing any machine learning system.
This stage of the validation process fits across all of the other validation stages discussed above. Having an appropriate ML validation process in place will provide a framework to be able to report on how a model has been validated at every stage. Hence meeting the compliance requirements.
Benefits of having an ML validation policy
Having a suitable validation process implemented across all five stages of the machine learning pipeline will ensure:
- Machine learning systems are built with and maintain high-quality,
- The systems are fully compliant and safe to use,
- All stakeholders have visibility on how a model is validated, and the value of machine learning.
Businesses should ensure they have the right processes and policies in place to validate the machine learning their technical teams are delivering. Additionally, Data Science teams should include validation design in the scoping phase of their machine learning system. This will determine the tests a machine learning model must pass to move, and remain in, production.
This will not only ensure businesses are generating a large amount of value of their machine learning systems, but also, allow non-technical business users and stakeholders to have trust in the machine learning applications being delivered. Therefore, increasing the adoption of machine learning across organisations.
If you would like to learn more about machine learning validation, or need help defining a ML validation policy within your organisation — please feel free to get in touch via Linkedin or email.
The 5 Stages of Machine Learning Validation was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
...