

 800+ IT
News
als RSS Feed abonnieren
800+ IT
News
als RSS Feed abonnieren📚 Into The Transformer
💡 Newskategorie: AI Nachrichten
🔗 Quelle: towardsdatascience.com
Into TheTransformer
The Data Flow, Parameters, and Dimensions

The Transformer — a neural network architecture introduced in 2017 by researchers at Google — has proved to be state-of-the-art in the field of Natural Language Processing (NLP) and subsequently made its way into Computer Vision (CV).
Despite many resources available online explaining its architecture, I am yet to come across a resource that talks explicitly about the finer details of the data as it flows through the Transformer in the form of matrices.
So, this article covers the dimensions (of inputs, outputs, and weights) of all the sub-layers in the Transformer. And at the end, the total number of parameters involved in a sample Transformer model is calculated.
Basic familiarity with the Transformer model is helpful but not mandatory to benefit from this article. Those who need further explanations on Transformer fundamentals can look at the references mentioned at the end of the article.
This article is organized as below:
- The Transformer
- Encoder
- Decoder
- The Peripheral Blocks
- Summary
1. The Transformer:
The Transformer consists of Encoder and Decoder, each repeated N times (the original research repeats it six times), as shown in Figure 1.
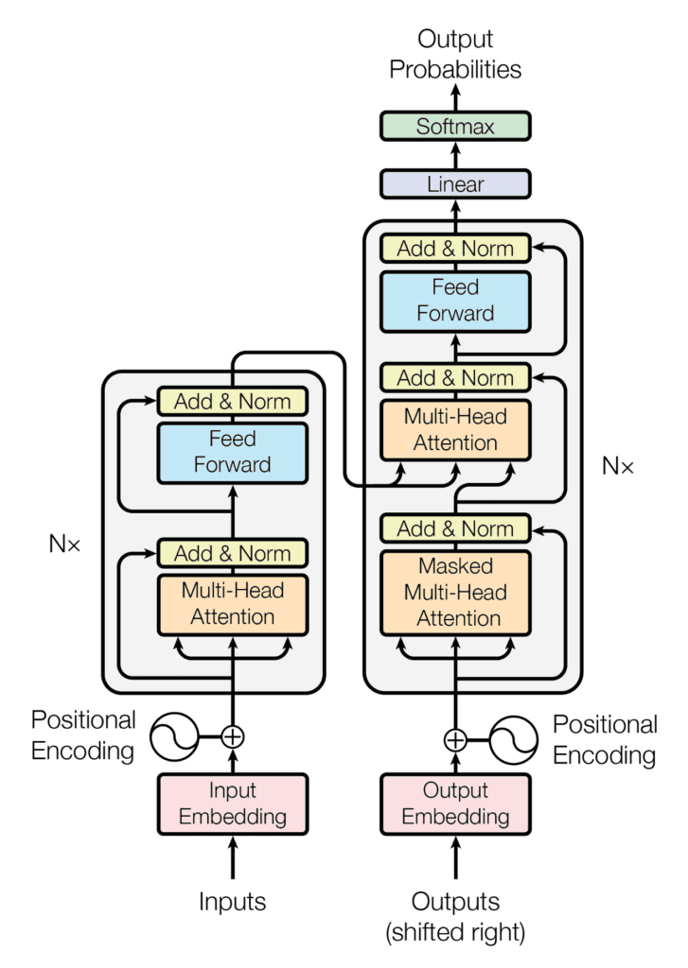
The data flows from the Encoder to Decoder, as shown in Figure 2.
The output of each Encoder is the input to the next Encoder. The output of the last Encoder feeds into each of the N Decoders. Along with the last Encoder’s output, each Decoder also receives the previous Decoder’s output as its input.
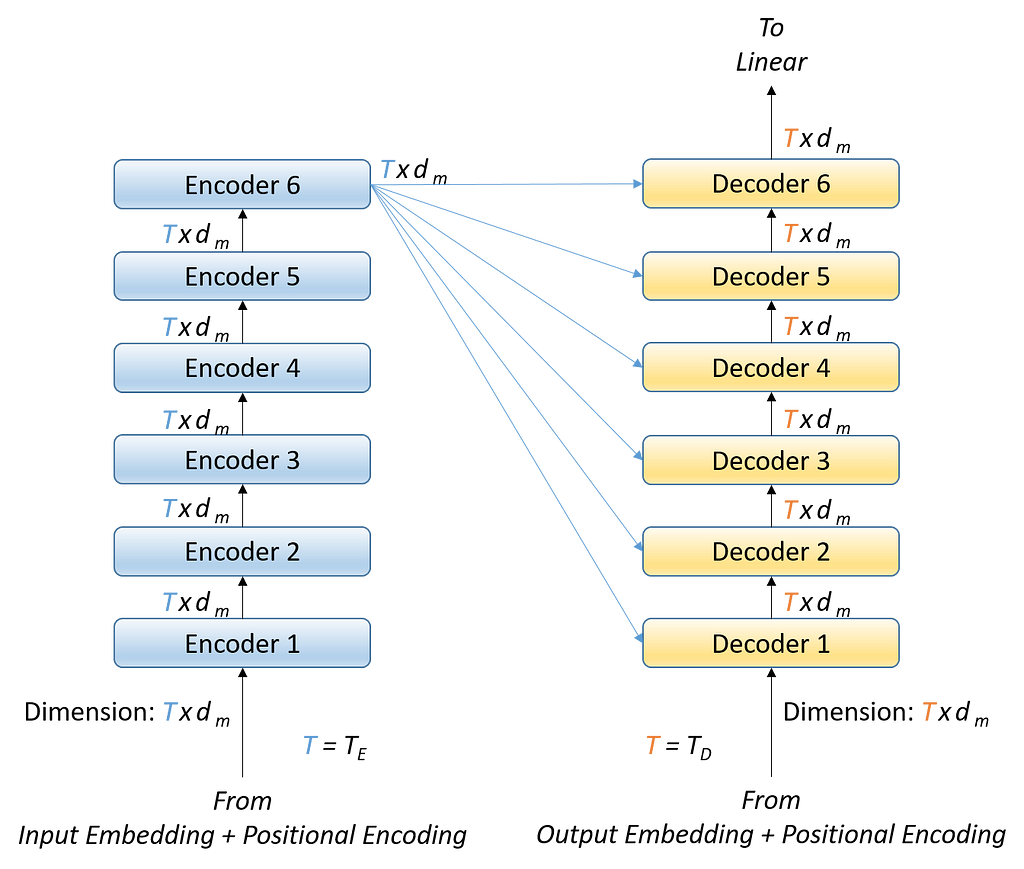
Now, let us look into the Encoder and Decoder to see how they produce an output of dimension Txdm by taking an input of the same dimension Txdm. Here, note that the number of inputs fed to the Encoder and the Decoder (TE and TD, respectively) can differ while the dimension of each input (both for the Encoder and for the Decoder) remains the same (i.e., 1xdm). More details on these dimensions are covered subsequently.
These Encoder and Decoder layers contain sub-layers within themselves.
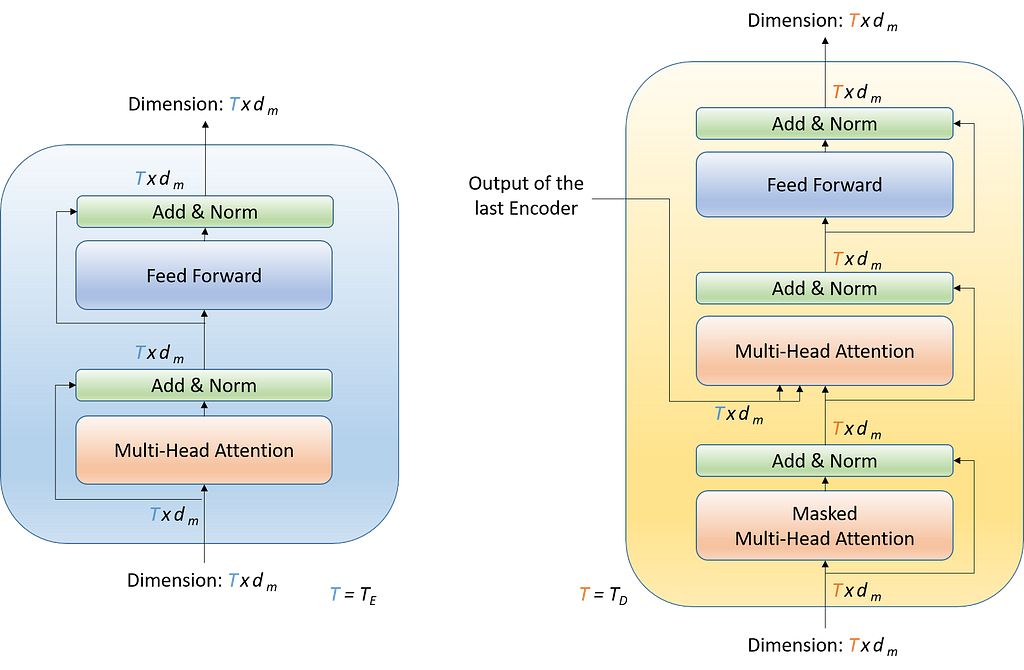
2. Encoder:
An Encoder has two sub-layers within.
- Multi-Head Attention
- Feed Forward
Multi-Head Attention in Encoder:
Multi-Head Attention is the crucial and the most computationally intensive block in the Transformer architecture. This module takes T (=TE) number of vectors of size 1xdm each as input (packed together into a matrix of size Txdm) and produces an output matrix of the same size Txdm (a pack of T number of vectors of size 1xdm each) as shown in Figure 4.
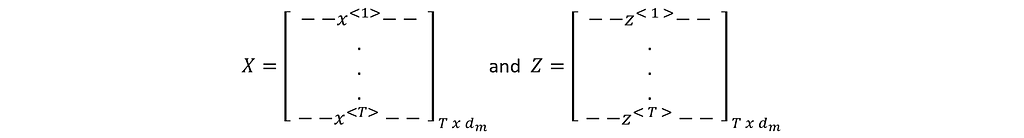
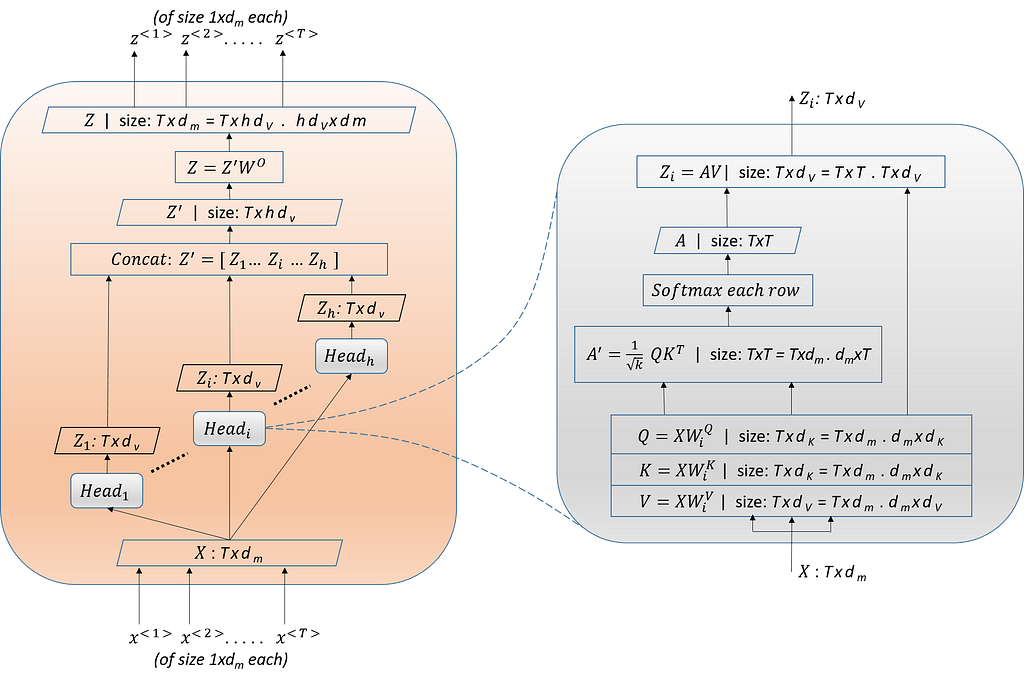
An attention head Head_i accepts (or the outputs from the previous Encoder) as input and produces Query, Key, and Value matrices by multiplying the input with the corresponding weight matrices.
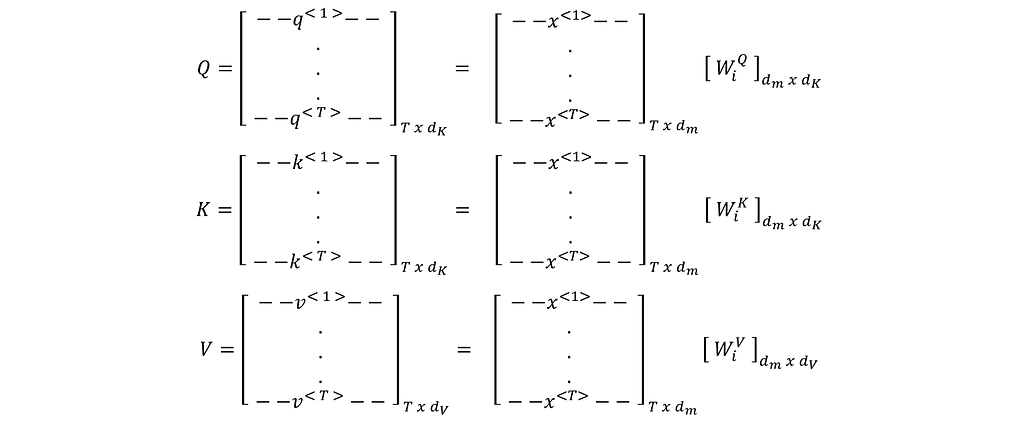
q<1>,k<1>, and v<1> are the projections of the x<1> through projection matrices wQ, wK, and wV and respectively. Similarly, for positions 2 to T.
and both are of dimension 1xdK while is of dimension 1xdV.
The elements of the matrix A’ are the scaled dot-products of each query vector q<> against every key vector k<>. (Dot-product between two vectors a and b of the same size is a.b = abT , wherebT is Transpose of b ).
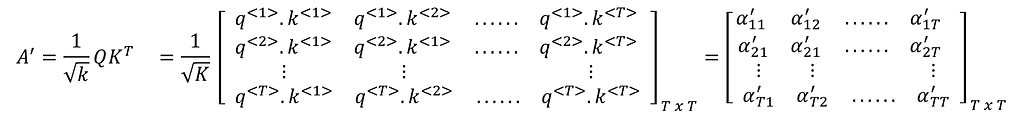
Applying Softmax on each row of the matrix A’ gives the matrix A. This is the Scaled Dot-Product Attention.
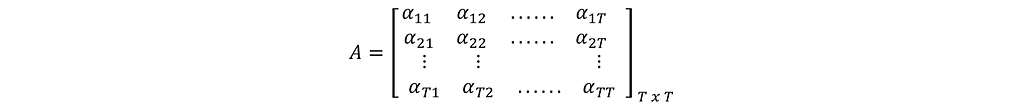
Elements in row-1 of A represent the Attention of query-1 against all keys from 1 to T. Row-2 is the Attention of query-2 against all keys, and so on. Each row in A sums up to 1 (being the output of Softmax).
Output of Head_i is the multiplication of the matrices A and V.
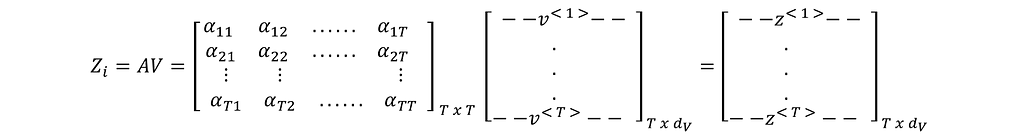
From the definition of matrix multiplication, row-1 of Zi is the weighted sum of all the rows of V with the elements from row-1 of A as the weights. Row-2 of Zi is the weighted sum of all the rows of V with the elements from row-2 of A as the weights, and so on. Note that the size of each row z<> is the same as the size of v<>. And there are as many rows in Zi as there are in A.
Now, the outputs of all the heads are concatenated to form Z’. And is multiplied by W⁰ to produce the final output of the Multi-Head Attention sub-layer, i.e., Z.

The dimension of each row in Z’ is 1xhdV (h number of vectors of size 1xdV are concatenated). The dimension of the matrix W⁰ is hdVxdm, which projects each row of Z’from 1xhdV dimension to 1xdm.
Thus, a Multi-Head Attention sub-layer in the Encoder takes an input of size Txdm (T number of inputs of 1xdm each) and produces an output of the same size Txdm (T number of outputs of 1xdm each). This is also referred to as Input-Input Attention or Encoder Self-Attention, i.e., each position of the input sentence attends to all the other positions of the input sentence itself.
Feed Forward Network in Encoder:
The Feed Forward Network takes an input of size Txdm (T number of inputs of 1xdm each) and implement the following function to produce an output of the same size Txdm. Here, T=TE.
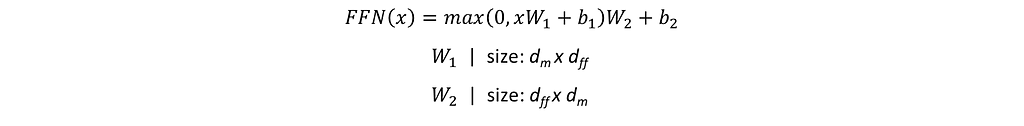
This network performs two linear transformations(by W1 and W2) with a ReLU nonlinearity in between. W1 transforms each of the inputs of dimension 1xdm into the dimension 1xdff, and transforms the 1xdff back into another 1xdm dimension.
Thus, the Feed Forward sub-layer produces an output of the same dimension as that of the input, i.e., Txdm.
3. Decoder:
A Decoder has three sub-layers within.
- Masked Multi-Head Attention
- Multi-Head Attention
- Feed Forward
Masked Multi-Head Attention in Decoder:
Masked Multi-Head Attention in a Decoder is also referred to as Output-Output Attention or Decoder Self-Attention. This module takes T (=TD) number of vectors of size 1xdm each as input and produces an output matrix Z of the same size Txdm. This is the same as the Multi-Head Attention sub-layer in Encoder (refer to Figure 4) except for one change — the masking. This mask prevents a query position from attending to the keys of future positions, preserving the auto-regressive property. So, a query q<t> is allowed to attend only to the keys from k<1> to k<t>. This is implemented by setting the positions of forbidden query-key combinations to -infinity in A’.
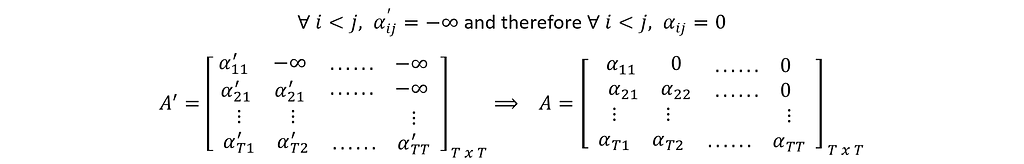
Thus, a Masked Multi-Head Attention sub-layer in the Decoder takes an input of size Txdm (T number of inputs of 1xdm each) and produces an output of the same size Txdm (T number of inputs of 1xdm each).
Multi-Head Attention in Decoder:
Multi-Head Attention in a Decoder is also referred to as Input-Output Attention or Encoder-Decoder Attention. This is the same as the Multi-Head Attention sub-layer in Encoder (refer to Figure 4), except that it receives an additional input (calling it XE) from the Encoder-Stack. This additional input (of size TExdm) is used to generate K and V while the input within the Decoder side (of size TDxdm) is used to generate Q.
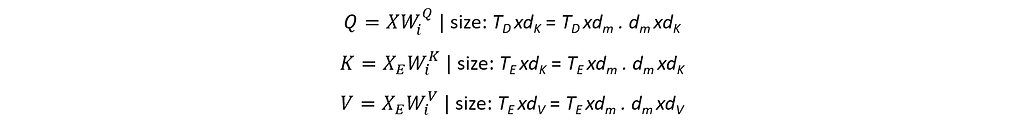
Accordingly, the dimensions of A’ and A also will change to TDxTE. This represents the attention of each of TD number of tokens from the Decoder side against every one of TE number of tokens from the Encoder side.
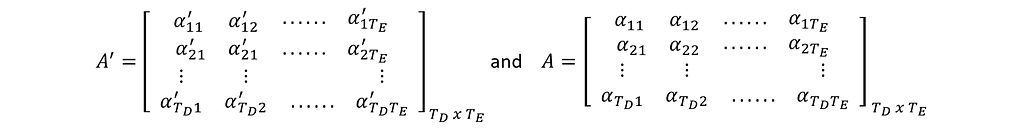
The output of the Head_i will be of dimension TDxdV .
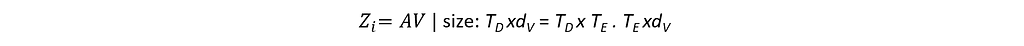
Feed Forward Network in Decoder:
Feed Forward Network in Decoder is the same as that in Encoder. Here, T=TD.
4. The Peripheral Blocks:
The other peripheral blocks in the transformer model are Input Embedding, Output Embedding, Linear, and Softmax blocks. Input Embedding (Output Embedding) converts the input-tokens (output-tokens) into a vector of the model-dimension 1xdm. Input and output tokens are one-hot encodings from the input and output dictionaries.
The Linear and Softmax block takes the input of dimension 1xdm from the last Decoder and converts it to a dimension equal to the one-hot encoding of the output dictionary. This output represents the probability distribution.
Positional Encoding neither consists of any learnable parameters nor does it alter the dimension by adding to the Embeddings. Hence, it is not explained any further.
5. Summary:
A Transformer model with Encoder-Decoder repeated 6 times and with 8 Attention Heads in each sublayer has the following parameter matrices.
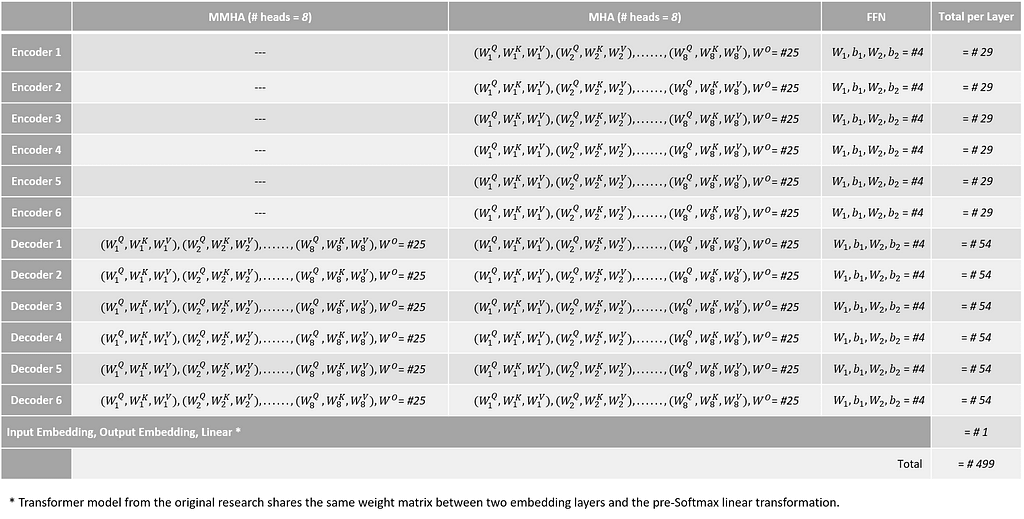
Generalizing the above for a model with N Encoder-Decoder layers and h Attention Heads:
- Number of parameter matrices per Encoder (MHA+FFN) = 3h+1 + 4 = 3h+5
- Number of parameter matrices per Decoder (MMHA+MHA+FFN) = 3h+1 + 3h+1 + 4 = 6h+6
- Number of parameter matrices for a single Encoder-Decoder pair = 3h+5 + 6h+6 = 9h+11
- Total number of parameter matrices of the model (NxEnc-Dec + Linear + I.Emb + O.Emb) = N(9h+11) + 3
Considering the dimensions of all the parameter matrices presented earlier, the total number of parameters of the model is as below:
- The number of parameters per Encoder:
MHA: (dmxdK + dmxdK + dmxdV)h + hdVxdm ----- (1)
FFN: dmxdff + 1xdff + dffxdm + 1xdm ----- (2)
- The number of parameters per Decoder:
MMHA: (dmxdK + dmxdK + dmxdV)h + hdVxdm ----- (3)
MHA: (dmxdK + dmxdK + dmxdV)h + hdVxdm ----- (4)
FFN: dmxdff + 1xdff + dffxdm + 1xdm ----- (5)
- The number of parameters in peripheral blocks:
Linear + I.Emb + O.Emb: I_dictxdm + O_dictxdm + dmxO_dict -- (6)
Here, I_dict is the input language dictionary size and O_dict is the output language dictionary size in Machine Translation.
- Total number of parameters of the model = N[(1)+(2)+(3)+(4)+(5)]+(6)
The base model mentioned in the original Transformer research paper (Attention Is All You Need) uses the dimensions dm = 512, dK = 64, dV = 64, dff = 2048, h = 8, N = 6 and has a total of 65 million parameters.
Conclusion:
Primarily, Transformers are used to build Language Models that help perform various NLP tasks such as Machine Translation, Automatic Summarization, Dialogue Management, Text-to-Image Generation and etc.
Several Large Language Models with billions of parameters, including the recent sensation — ChatGPT — that demonstrated exceptional conversational capabilities, have Transformers as their building block.
I hope looking into this building block allowed you to conceive how these Large Language Models end up containing billions of parameters.
References:
[1] Jay Alammar, Illustrated Transformer Blog Post, 2018.
[2] Vaswani et al., Attention Is All You Need, 2017.
Into The Transformer was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
...