

 800+ IT
News
als RSS Feed abonnieren
800+ IT
News
als RSS Feed abonnieren📚 Transform Your NLP Game
💡 Newskategorie: AI Nachrichten
🔗 Quelle: towardsdatascience.com
Learn and improve NLP skills by building your own encoder from scratch

There is currently a lot of hype surrounding artificial intelligence (AI) thanks to technologies like ChatGPT. The Transformers, which serve as the fundamental building blocks for many recent popular AI applications, are at the center of this hype. That is why I am writing this article about them. Transformers are deep learning models that have excelled at a variety of natural language processing tasks and are the preferred choice for many industry professionals.

Table of Contents
- Important Stuff to Know
- The Encoder-Decoder Framework
- Attention Mechanisms
- Transfer Learning - Creating Our Own Transfomer Encoder
- Tokenizer
- Attention and Multi Head Attention
- Transformer Layer
- Positional Encodings
- Encoder Block
- Utility Functions and Classification Head - Transformers in Action
- Test Results - Conclusion
- References
The Transformer architecture was introduced in the 2017 paper “Attention is All You Need” by Vaswani et al. [1] This paper has been the driving force behind some of the most influential natural language processing models of recent times, including the Generative Pre-trained Transformer (GPT) and Bidirectional Encoder Representations from Transformers (BERT). These models have transformed the field of natural language processing and have been widely adopted in various applications. Researchers are still working to improve upon these powerful tools as they continue to push the boundaries of what is possible.
In this article, we will examine how to implement transformers from scratch, starting with the basic building blocks and gradually working up to more complex architectures. By building our own transformer, we can gain a deeper understanding of how these models work and apply them to different tasks and datasets. In the process, we will also learn about the key concepts and techniques that make transformers so effective. This article will provide valuable insights into the world of transformers, whether you are a beginner or an experienced practitioner.
To fully understand the concept of transformers, it is essential to understand the following three key components:
- The encoder-decoder framework
- Attention mechanisms
- Transfer learning
To start, let’s examine the encoder-decoder framework and the architectural developments that paved the way for the emergence of transformers.
The Encoder-Decoder Framework
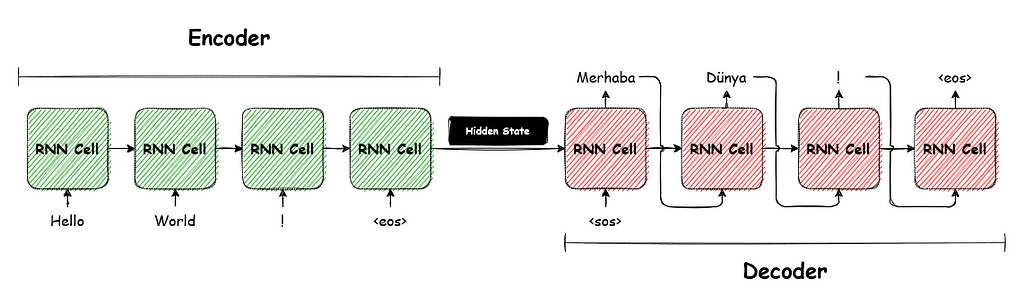
Before we delve into the encoder-decoder framework, let’s take a look at a special kind of neural network. The following quote, based on the book “Deep Learning” by Goodfellow, Bengio, and Courville, sums it up well enough:
Recurrent neural networks or RNNs are a family of neural networks for processing sequential data, such as natural language or time series data. At each time step, the RNN receives an input, which could be a single word or character in the case of natural language processing. The RNN processes the input and updates a hidden state vector, which captures information about the input sequence up to that point. The hidden state is then used to produce an output that can be used for various tasks at hand.
One key characteristic of an RNN is its feedback loop, which allows it to retain information from previous time steps and use it to make decisions at the current time step. This enables the RNN to “remember” past inputs and context, which is crucial for tasks such as language translation or language generation, where understanding the meaning and context of a word or phrase depends on the words and phrases that came before it.
Sequence-to-sequence architectures are well-suited for situations in which the input and output sequences have variable lengths. These architectures work by processing the input sequence with an encoder, which converts it into a fixed-length representation called the hidden state. This hidden state is then passed to a decoder, which generates the output sequence based on the encoded representation.
Encoder-decoders with RNNs are relatively simple, but there is one major issue with this approach. As the input sequence becomes longer, the hidden state must retain more and more information about the past inputs in order to accurately predict the next output. However, if the capacity of the RNN is insufficient to represent this information, the hidden state can become “bottlenecked,” which can cause the RNN to struggle to accurately predict the next output.
Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) networks were developed to address the issue of the information bottleneck in traditional RNNs. These architectures include more sophisticated mechanisms for storing and retrieving information. Finally, the attention mechanism, a key component of transformers, was able to solve this bottleneck.
Attention Mechanisms
I’ll briefly touch on this subject because we’ll be implementing the attention mechanism itself later in the article. In any case, attention mechanisms are neural network layers that enable a model to focus on specific parts of an input while processing it. Attention mechanisms have been widely used to improve the ability of models to understand and generate text in natural language processing tasks such as machine translation, language modeling, and text summarization. They can also improve the performance of deep learning models in computer vision and speech recognition tasks by allowing the model to focus on the most relevant parts of an input. It’s worth noting that there is also a type of attention mechanism called “self-attention,” which allows a model to attend to different parts of the input sequence when generating an output.
Transfer Learning
Most of you should be familiar with this, so I don’t think a detailed explanation is necessary at this point:
Transfer learning is a machine learning technique that involves training a model on a large dataset before fine-tuning it for a specific task. In transfer learning for NLP, a pre-trained model is often first trained on a large dataset, such as a dataset of common crawl data or Wikipedia articles. For example, in tasks like “Masked Language Modeling” (MLM), a subset of tokens are randomly masked and fed into the model, and the model attempts to guess the original token based on the given sequence. By pre-training on tasks like MLM, the model can learn a rich representation of language by being trained on a large and diverse dataset.
Creating Our Own Transfomer Encoder
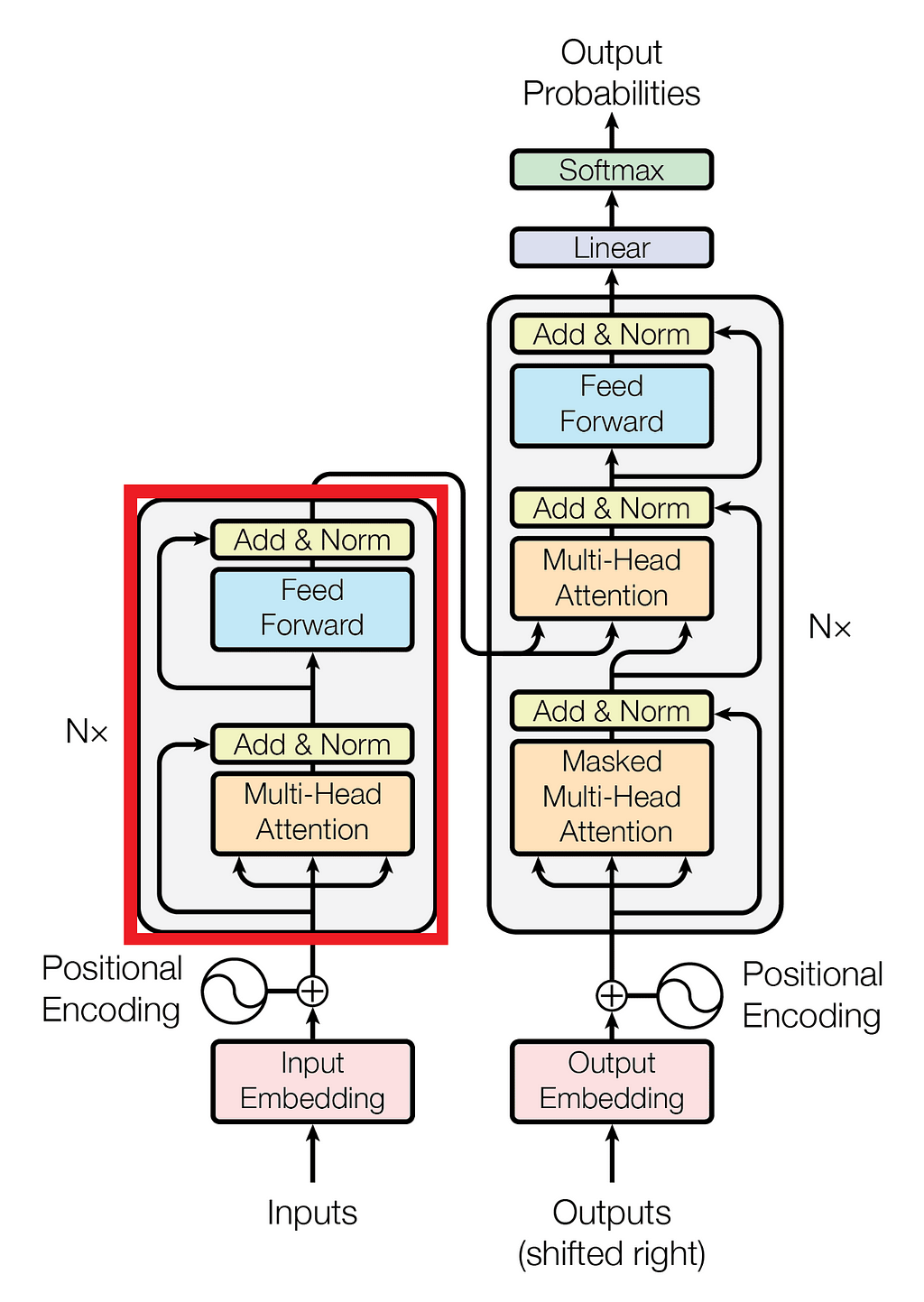
In this part, we’ll create and fit the pieces of the puzzle to build our own encoder block! The main task flow should look like this:
- Create a simple tokenizer and vocabulary.
- Implement critical Transformer layer components such as the scaled dot product, attention, multi-head attention heads, and the feed-forward layer.
- Assemble the transformer layer using these implemented pieces.
- Use the transformer layer multiple times to build the encoder block.
Tokenizer
Tokenization is the process of breaking down a string of text into smaller pieces called tokens. These tokens can be individual words, phrases, or subwords. Tokenization is a crucial preprocessing step in natural language processing; in order to input sequences into a transformer model, they must first be converted into a numerical representation that the model can understand. That’s where tokenization comes in.
By tokenizing the input text, we can convert it into a sequence of integers that represent the individual tokens. This allows the transformer model to process the input text as a sequence of tokens rather than a single string of text. There are three main types of tokenization:
- Character tokenization
- Word tokenization
- Subword tokenization
Each of these types has its own advantages and disadvantages. Character tokenization is simple, but it lacks knowledge of actual words. Word tokenization has knowledge of words, but it requires a large vocabulary to handle all possible variations of every single word in the corpus. Subword tokenization falls somewhere in between these two approaches, as it divides words into smaller subwords based on a predefined vocabulary. This allows the model to handle out-of-vocabulary words while keeping the vocabulary size manageable, and it is the most widely used method. For simplicity, we will use word tokenization.
https://medium.com/media/ae8b1352cf617859a3d4e9939ae9e99f/hrefThere’s a large piece of code here, but don’t worry! It’s actually a simple class that does exactly what we want from a word tokenizer. By using the fit_on_corpus method, it maps each unique word to an index in a dictionary internally, and this will be our vocabulary. We’ve also added some special tokens to handle unknown tokens and attention maps. Then, we have the encode method, which takes a string and returns unique indices from our vocabulary that we can use as a lookup table. The next methods are mostly for utility purposes; the tokenize method tokenizes the given text using the nltk library. In this case, a tokenized string is a list of words. The following lines pad or truncate the text by the given max_len argument, ensuring that all sequences are the same length for batch processing during training. The vocab_size property gives us the size of our vocabulary, which we’ll use in the future for our transformer model.
The next step will be creating our vocabulary using a corpus. Normally, transformer vocabularies are created from huge datasets like Wikipedia articles, books, or a combination of different public text sources. But for our simple example, we’ll use the Large Movie Review Dataset from Stanford. The dataset contains 50k movie reviews that have been labeled as positive or negative.
# Loading the dataset as pandas dataframe
df = pd.read_csv('IMDB Dataset.csv')
# Initialize the tokenizer
tokenizer = WordTokenizer(max_len=256)
# Fit the tokenizer on a corpus of texts
tokenizer.fit_on_corpus(df.review.tolist())
# Update the config vocab_size
config.vocab_size=tokenizer.vocab_size
print(tokenizer.word_to_index)
### Output:
{'<pad>': 0,
'<unk>': 1,
'mouth-foamingly': 2,
'abroad.': 3,
'…':
'terry/carey':163857,
'libertine':163858
}
We’ve just created our first vocabulary using the word tokenizer we implemented. As you can see, it maps each unique word to an index, which we can use to embed our string sequences into dense vectors. However, you can see the downside of using this word tokenization method with larger datasets. For example, with 50k reviews, we ended up with around 163k unique word tokens. This is why subword tokenization is often used instead. With that technique, theoretically, our tokenizer would create tokens like [‘mouth’, ‘foam’, ‘###ingly’]. This way, if ‘foam’ is used in different forms, it’s kept as one index instead of keeping track of every single modification. However, for the purposes of this tutorial, our approach is sufficient.
Okay, let’s test our encoder on a test sentence with a typo to see if it’s working:
tokenizer.encode('This is a twest, sorry a test sentence!')
### Output:
{'input_ids': tensor([[ 45594, 30562, 41753, 1, 111258, 89975, 41753, 53047, 27998,
55328, 0, …, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, …, 0]])}Yep, it’s working as intended! So it returns input_id’s for each token, 1 as a <unk> special token for our typo, and 0 for padded parts up to our specified max_len. It also returns an attention mask, which is 1 for attended tokens and 0 for a <pad> special token.
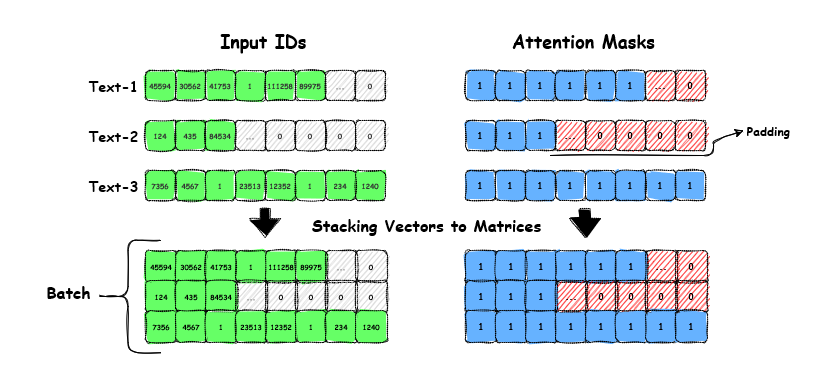
Now that we have a working tokenizer, we can proceed to the next part of our article. In the following section, we will focus on constructing the key components of the transformer, which will eventually lead to the creation of the encoder block.
Attention and Multi Head Attention
One issue with tokenization is that a language model may struggle to understand the context of individual tokens. For example, a pronoun may refer to a specific noun earlier in the text, and a homonym like “ruler” may have multiple meanings depending on the context. This is where attention mechanisms, especially self-attention, come in. With attention, the model is able to understand the context of each token by considering its relationship to other tokens in the sequence. For example, if the model encounters the word “ruler” in a string of words related to history or politics (such as “queen,” “king,” or “country”), it may interpret it as referring to a political role. In contrast, if the word is surrounded by words related to measurement (such as “centimeter” or “length”), the model may understand “ruler” as a physical object used for measuring.
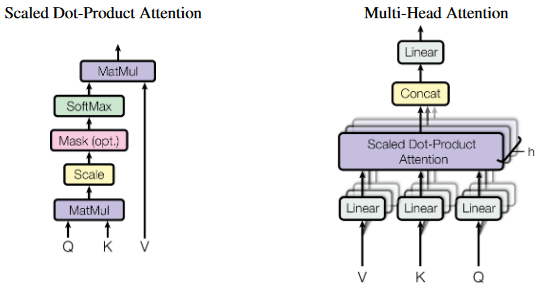
Let’s get started by implementing our first instance of attention head:
https://medium.com/media/08168bf9e46c4af93b935aa2c6a7c5d2/hrefThe AttentionHead class has two main components:
- Three linear layers: These are used to transform the input (hidden_state) into three different representations: query, key, and value vectors. The head_dim is the number of dimensions that we project the input into, and it is usually chosen to be a multiple of embded_dim and num_heads. The self-attention layer in this case projects the embeddings and uses its own set of learnable parameters to focus on various semantic aspects of the sequence, enabling it to analyze and understand the input in more depth (instead of giving the highest score to identical vectors). These representations are then used to calculate the attention weights, as described below.
- The scaled_dot_product_attention: This method takes the query, key, and value representations and calculates the attention weights. It does this by first calculating the dot product (similarity measure) between the query and key representations, then dividing by the square root of the dimension of the key representation (dim_k). This is known as scaling the dot product, and it helps stabilize the gradient during training. The dot product is then passed through a softmax function (to ensure that all the column values sum to 1) to calculate the attention weights. Finally, the attention weights are multiplied with the value representation to produce the final output.
And finally, forward method that gets called when the AttentionHead module is used in a forward pass in the model. It calls the scaled_dot_product_attention method with the hidden_state input, passing the transformed query, key, and value representations as arguments. The output of the scaled_dot_product_attention method is then returned as the output of the AttentionHead module.
The approach above would give us scores for one aspect of similarity. However, in natural language there are many aspects, so having multiple heads (multiple sets of projections) may help us overcome this. This is where the MultiHeadAttention comes in:
https://medium.com/media/129f24d73e7b972359b3fe068c92af41/hrefThere isn’t much to explain here. Rather than using a single attention head, we create multiple attention heads (the number is determined by the configuration) to capture different aspects of the given sequence. For example, one of the model’s heads may concentrate on the subject-verb relationship, while another searches for nearby adjectives. And we are left with the last missing piece of the Transformer: if we skip the skip connections (gotcha!) and don’t count the layer normalizations, the feed-forward layer:
https://medium.com/media/da9cfaad1486cbd2d1e7b2fd5e9c8293/hrefIn the Transformer, the FeedForward is a sublayer that processes each embedding independently. It is common practice to set the hidden size of the first layer (intermediate_size) to be four times larger than the embedding size (hidden_size). This helps the model effectively process, understand, and especially memorize the input data.
Our first Transformer Layer!
Drumrolls…
Here it is! When we put all of the pieces together, we get the part from the original paper where we pointed earlier. Here’s the code:
The implementation is almost identical to the original paper implementation, as are many current applications. Instead of using post-layer normalization like the original paper, we only applied layer normalization within the span of the skip connections, which is usually more stable during the training phase[2].
Now that we’ve implemented a Transformer layer from scratch, it’s amazing to think that such a simple piece of code has revolutionized the entire industry in the past couple of years and is still going strong.
Positional Encodings
We can create a custom embeddings module that combines a token embedding layer and a positional encoding layer. The token embedding layer projects the input_ids to a dense hidden state, while the positional encoding layer does the same for position_ids. This results in a hybrid approach that combines both token and positional information in the input data.
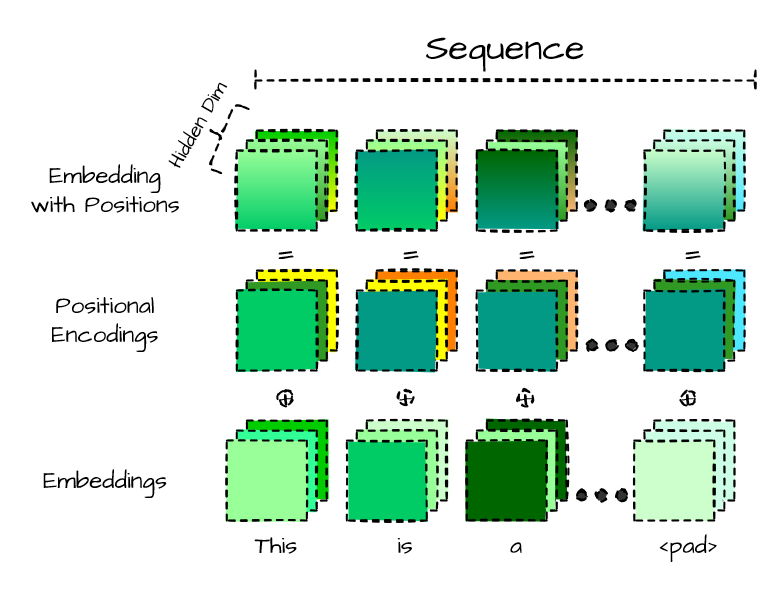
Positional encodings operate similarly to token embeddings, but instead of using token IDs as input, they use position indexes. This enables the encoder layers to incorporate positional information into their transformations, allowing them to more effectively process the input data.
https://medium.com/media/953f215fe41ee95c9506b45934035007/hrefIn this code, we’ve implemented learnable positional encodings which are easy to use. However, there are other options for positional encodings that we could consider, such as the absolute positional representations used in the original Transformer paper, or more advanced methods like the relative positional representations used in the DeBERTa model. While these may offer additional benefits, the learnable positional encodings we’ve implemented will suffice for our tutorial.
Finalized Encoder Block
https://medium.com/media/76b8f69d2e2f3d5a3675a260e7388097/hrefBy adding token embeddings that include positional representations and stacking the encoder layers according to a predetermined number, we can create the final version of our encoder. The purpose of stacking the encoder layers is to update the input embeddings in order to produce representations that encode contextual information within the sequences. With a few minor adjustments and updates, this module should be able to learn and train on the given data, as we will demonstrate in subsequent sections.
Utility Functions and Classification Head
A problem we must address before adding a classification head is the fact that transformer models return one embedding vector per token, with the vector size determined by the configuration. For instance, given the sentence “Hello, world!” we would receive two embedding vectors, one for each token. But in our movie review case, we want a single embedding vector for the entire review. To solve this issue, we can use a technique called pooling. One of the most straightforward pooling methods is to average the token embeddings, which is called mean pooling.
https://medium.com/media/b882813f7a7ead1d0adb9b7c82f7c070/href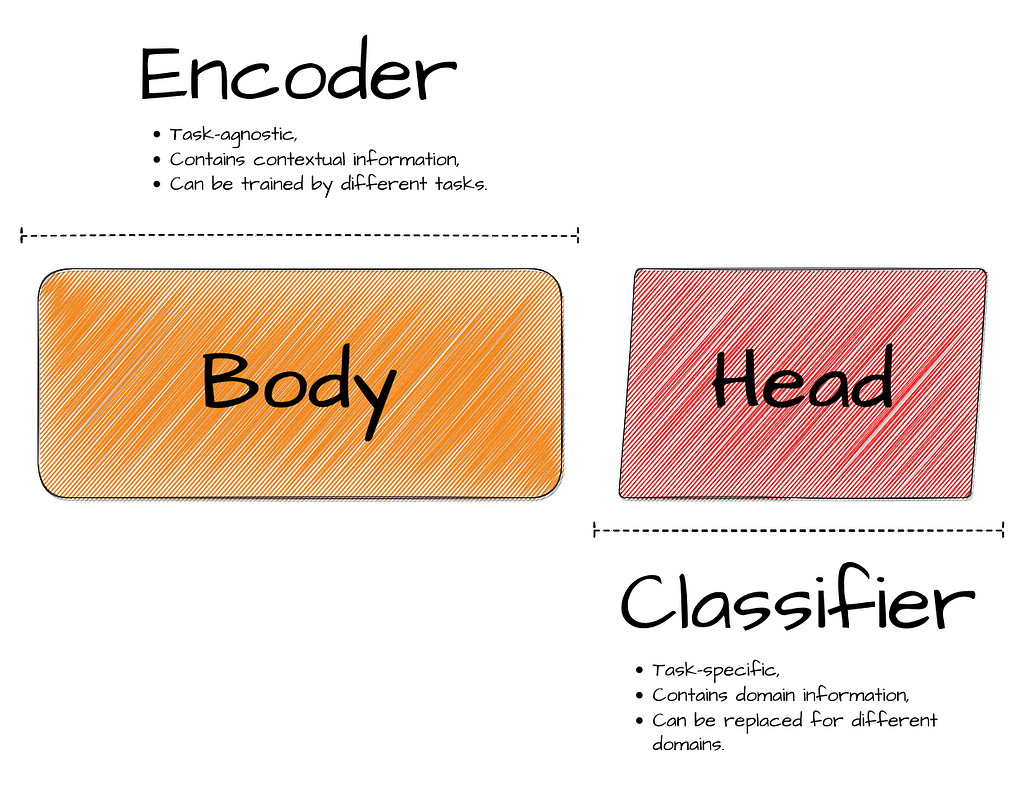
We have completed the task-agnostic portion of our model, called model body. The final step is to add a task-specific layer, known as the model head. In our case, this is simply a dense layer that returns logits based on the output of the mean-pooled embeddings from the model body.
https://medium.com/media/a584729db3d8e2bb4f6cda31eac22657/hrefWith all the necessary components in place, we are now ready to train our movie review dataset and evaluate the results. The next section will cover the typical classification process using PyTorch.
Transformers in Action
I won’t go into the specifics of the training process here because it follows a simple PyTorch pipeline; but in summary it works like this:
- Split the train and test data using sklearn.
- Create a dataloader to read and tokenize the text on the fly.
- Use a basic PyTorch training loop to update the model weights using binary cross entropy loss and the Adam optimizer for a specified number of epochs.
There are a number of ways we could improve the model, such as increasing number of encoder layers, using better hyperparameters, implementing early stopping, and using more advanced optimizers and training rate schedulers for transformers like AdamW and the cosine scheduler with warm up. If you want to try and improve the results, I encourage you to experiment with these techniques yourself.
Test Results
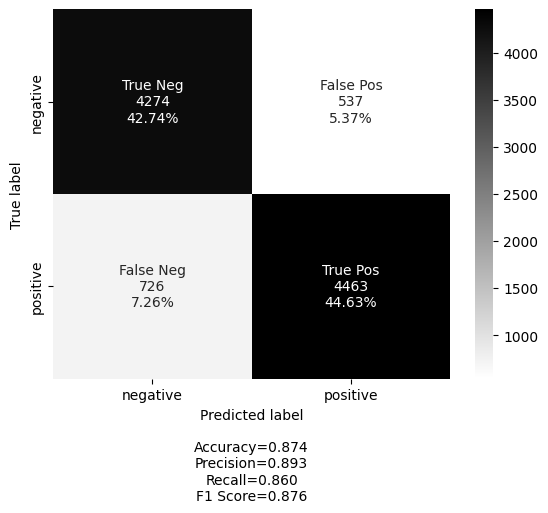
Here are the results of our shallow transformer model, which used only one encoder layer and a basic tokenizer. Despite not being pretrained on a large corpus, the model performed exceptionally well, showcasing the ability of transformer models to capture contextual information effectively. Additionally, the model body can be trained on tasks like masked language modeling or next sentence prediction, making it more versatile and able to be used for various tasks without the need for significant modifications. This is especially useful when the same model body is used for different tasks. The versatility and strong performance of transformer models make them a valuable tool in natural language processing.
Conclusion
In this article, we covered the encoder part of transformers in depth, building each component from scratch and applying it to a real NLP classification problem. The only missing piece is the decoder part, which generates sequences using a given prompt or sequence. It is similar to the encoder block in implementation, with the main differences being the use of masked multi-head attention and encoder-decoder attention.
I hope that this article gave you a deeper understanding of transformer models and their inner workings. I enjoyed writing it and hope that you enjoyed reading it as much as I did.
References:
Transform Your NLP Game was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
...