

 800+ IT
News
als RSS Feed abonnieren
800+ IT
News
als RSS Feed abonnieren📚 Character Encoding in NLP: The Role of ASCII and Unicode
💡 Newskategorie: AI Nachrichten
🔗 Quelle: towardsdatascience.com
A closer look at the technicalities and practical applications
Introduction
In this article we will cover the topic of character encoding standards, specifically focusing on the ASCII and Unicode systems. We will dive into how they work and their role in deep learning. In addition, we will provide some examples of character encoding using Tensorflow, to have an overview of how this library manages strings on the inside.

But first of all, we will present some important concepts.
What is a character encoding standard?
Character encoding is a system for representing characters as numerical values, known as code points. These code points allow computers to store and manipulate text, which can then be displayed or used in other ways. In this article, we will explain the ASCII and Unicode character encoding systems and discuss their usefulness in the field of natural language processing (NLP).
ASCII
ASCII (American Standard Code for Information Interchange) is a character encoding standard that assigns unique numbers to each letter, digit, and other symbol used in written text. It is widely used, but it has some limitations.
ASCII has 128 code points, which means that it can represent 128 characters and symbols. Some of these code points represent instructions for the computer, while others represent printable characters such as letters and digits.
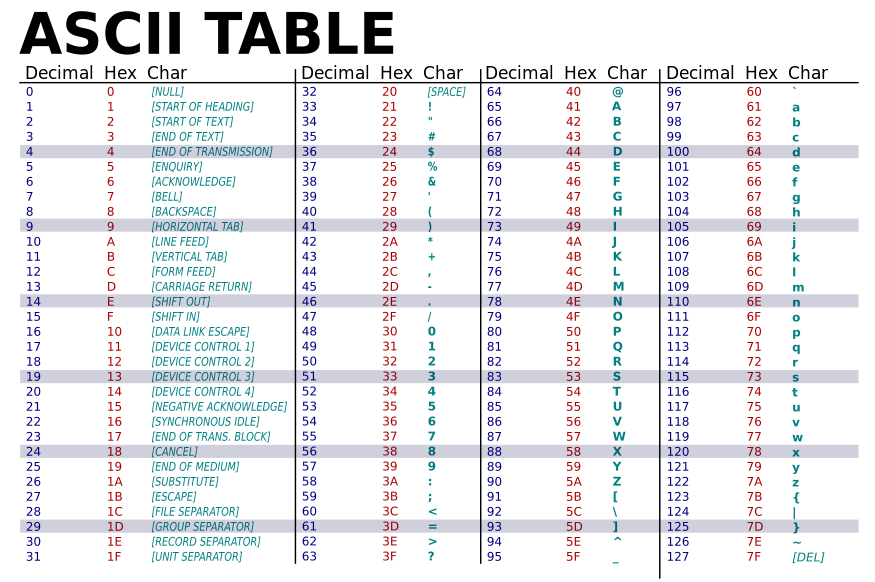
The mapping system used in ASCII can be found in this table:
{kind=link}
As we can see, out of 128 code points, only 94 are printables.
For example, using the hexadecimal column of this table, we can encode the string “Language” as “4C 61 6E 67 75 61 67 65”.
Limitations of ASCII
The main limitation of ASCII code as we said earlier is that it only has 94 printable characters. These include upper and lower case English letters (52 characters), digits (10 characters), and punctuation marks and symbols (32 characters). So ASCII is not suited for any language that uses more than the basic Latin alphabet. There are different characters in other languages (Chinese, Russian, Norwegian), or even accented letters in languages such as French and Spanish, for example, that can not be displayed using this character encoding system. Also, there are special symbols, like emojis or currency symbols that are not included in ASCII either, which limits its potential. For those reasons, a new character encoding system was required, to make it more extensible and have taken into account all these characters and symbols that have been forgotten in the ASCII code. This is where the Unicode Standard arises.
Unicode
Unicode is a character encoding standard developed in the late 1980s and early 1990s to expand upon the capabilities of ASCII and other existing standards. One of the main motivations for its development was the need to have a single-character encoding standard that could be used to represent text in any language. To address this problem, the Unicode consortium was formed, to create a single, universal character encoding standard that could represent all the world’s languages. Unicode uses a 16-bit encoding scheme, which allows it to represent over 65,000 different characters. This is significantly more than the 128 characters that can be represented using ASCII. It has since become the dominant character encoding standard for the WWW and is widely supported by modern computing systems and software. It can encode and display text in a wide range of languages, including those using scripts other than the Latin alphabet (e.g. Chinese, Japanese, Arabic), as well as special symbols like emojis and currency symbols.
You can find more information on their website.
How does it work?
Unicode defines a codespace, a set of numerical values ranging from 0 through 10FFFF (in hexadecimal), called code points and denoted with a U at the beginning, so it ranges from U+0000 to U+10FFFF. We will use the U followed by the code point value of the character in hexadecimal and use it for digits (with leading zeros if necessary, e.g., U+00F7). The Unicode codespace is divided into seventeen planes, numbered 0 to 16. Each plane consists of 65,536 (2¹⁶) consecutive code points. Plane 0, known as the Basic Multilingual Plane (BMP), contains the most commonly used characters. The remaining planes (1 to 16) are called supplementary planes. Within each plane, characters are allocated within named blocks of related characters. A Unicode block is one of several contiguous ranges of numeric character codes. They are used to organize the vast number of characters in the Unicode standard. Each block is generally, but not always, meant to supply glyphs used by one or more specific languages, or in some general application area.
Mapping and encodings
Unicode defines two mapping methods: UTF encodings and UCS encodings. An encoding maps the range of Unicode code points to a sequence of values within a fixed range. All UTF encodings map code points to a unique sequence of bytes. The number in the names of the encodings indicates the number of bits per code unit. UTF-8 and UTF-16 are the most commonly used encodings.
- UTF-8 uses one to four bytes for each cope point. It is very compatible with ASCII.
- UTF-16 uses one or two 16-bit code units per code point.
Unicode in NLP
In this section, we will see how to use Unicode in NLP tasks and how is it useful. We will use some Tensorflow code to make these examples more illustrative.
NLP models often handle different languages with different character sets. The most representative task could be Neural Machine Translation (NMT), where the model has to translate sentences into other languages. But in general, all language models have to use string sequences as input, so Unicode is a pretty important step. Using Unicode representation is generally the most effective choice.
Here we will see how to represent a string in Tensorflow and manipulate them using Unicode. The basic TensorFlow tf.string type allows us to build tensors of the byte string. Unicode strings are UTF-8 by default.
tf.constant(u"Hello world 🌎")
>>> tf.Tensor(b'Hello world \\xf0\\x9f\\x8c\\x8e', shape=(), dtype=string)
Here we can see that the emoji is encoded as “\xf0\x9f\x8c\x8e”. It is represented in UTF-8.
Representation
We can represent a Unicode string in Tensorflow in two standards:
- string scalar — where the sequence of code points is encoded using a known character encoding (such as Unicode).
- int32 vector — where each position contains a single code point.
For example, the following values all represent the Unicode string “语言处理” (which means “language processing” in Chinese).
# Unicode string, represented as a UTF-8 encoded string scalar
text_utf8 = tf.constant(u"语言处理")
print(text_utf8)
>>> tf.Tensor(b'\\xe8\\xaf\\xad\\xe8\\xa8\\x80\\xe5\\xa4\\x84\\xe7\\x90\\x86', shape=(), dtype=string)
And we can also represent it using UTF-16.
# Unicode string, represented as a UTF-16-BE encoded string scalar
text_utf16be = tf.constant(u"语言处理".encode("UTF-16-BE"))
print(text_utf16be)
>>> tf.Tensor(b'\\x8b\\xed\\x8a\\x00Y\\x04t\\x06', shape=(), dtype=string)
And finally, in a vector of Unicode code points.
# Unicode string, represented as a vector of Unicode code points
text_chars = tf.constant([ord(char) for char in u"语言处理"])
print(text_chars)
>>> tf.Tensor: shape=(4,), dtype=int32, numpy=array([35821, 35328, 22788, 29702], dtype=int32)
Conversion
Tensorflow provides operations to convert between these different representations:
- tf.strings.unicode_decode: Converts an encoded string scalar to a vector of code points.
text_chars_converted = tf.strings.unicode_decode(text_utf8, input_encoding='UTF-8')
print(text_chars)
print(text_chars_converted)
>>> tf.Tensor([35821 35328 22788 29702], shape=(4,), dtype=int32)
>>> tf.Tensor([35821 35328 22788 29702], shape=(4,), dtype=int32)
- tf.strings.unicode_encode: Converts a vector of code points to an encoded string scalar.
text_utf8_converted = tf.strings.unicode_encode(text_chars, output_encoding='UTF-8')
print(text_utf8)
print(text_utf8_converted)
>>> tf.Tensor(b'\\xe8\\xaf\\xad\\xe8\\xa8\\x80\\xe5\\xa4\\x84\\xe7\\x90\\x86', shape=(), dtype=string)
>>> tf.Tensor(b'\\xe8\\xaf\\xad\\xe8\\xa8\\x80\\xe5\\xa4\\x84\\xe7\\x90\\x86', shape=(), dtype=string)
- tf.strings.unicode_transcode: Converts an encoded string scalar to a different encoding.
text_utf16be_converted = tf.strings.unicode_transcode(text_utf8, input_encoding='UTF-8', output_encoding='UTF-16-BE')
print(text_utf16be)
print(text_utf16be_converted)
>>> tf.Tensor(b'\\x8b\\xed\\x8a\\x00Y\\x04t\\x06', shape=(), dtype=string)
>>> tf.Tensor(b'\\x8b\\xed\\x8a\\x00Y\\x04t\\x06', shape=(), dtype=string)
Character length
We can use the unit parameter of the tf.strings.length operation to indicate how character lengths should be computed. The default unit value is “BYTE”, but it can be set to other values such as “UTF8_CHAR” or “UTF16_CHAR”, to determine the number of Unicode code points in each encoded string.
# Note that the final character (emoji) takes up 4 bytes in UTF8.
helloWorld = u"Hello World 🌍".encode('UTF-8')
print(helloWorld)
>>> b'Hello World \\xf0\\x9f\\x8c\\x8d'
num_bytes = tf.strings.length(helloWorld).numpy()
num_chars = tf.strings.length(helloWorld, unit='UTF8_CHAR').numpy()
print('{} bytes; {} UTF-8 characters'.format(num_bytes, num_chars))
>>> 16 bytes; 13 UTF-8 characters
If you count the number of bytes in the string “Hello World \xf0\x9f\x8c\x8d” (counting each letter, space, and byte) you will see that there are 16 bytes as we can see in the output code.
This string has 13 UTF-8 characters if we count the same as before but count the emoji as one character and not 4 bytes.
If you want a more complete tutorial about this section, I recommend you to visit this TensorFlow tutorial.
Unicode strings | Text | TensorFlow
Conclusion
In conclusion, the character encoding is an essential aspect of computer systems and natural language processing (NLP). ASCII is a widely used standard that assigns unique numbers to each letter, digit, and symbol in the text, but it has limitations in its representation of characters. The Unicode standard was developed to address the limitations of ASCII, by using a 16-bit encoding scheme that allows it to represent over 65,000 different characters and support text in any language. Unicode has since become the dominant character encoding standard for the World Wide Web and modern computing systems and is essential for displaying and processing text in a wide range of languages and symbols. In this article, we have seen a detailed overview of the ASCII and Unicode encoding systems, and how Tensorflow manages the strings in Unicode.
If you have any doubts or suggestions please leave a comment. Thanks for reading!
Character Encoding in NLP: The Role of ASCII and Unicode was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
...