

 800+ IT
News
als RSS Feed abonnieren
800+ IT
News
als RSS Feed abonnieren📚 Migrating Elasticsearch’s warm & cold data to object storage with JuiceFS
💡 Newskategorie: Programmierung
🔗 Quelle: dev.to
With the development of cloud computing, object storage has gained favor with its low price and elastic scalable space. More and more enterprises are migrating warm and cold data to object storage. However, migrating the index and analysis components directly to object storage will hinder query performance and cause compatibility issues.
This article will elaborate the fundamentals of hot and cold data tiering in Elasticsearch, and introduce how to use JuiceFS to cope with the problems that occur on object storage.
1 Elasticsearch’s data tier architecture
There are three concepts to be known before diving into how ES implements a hot and cold data tiering strategy: Data Stream, Index Lifecycle Management (ILM), and Node Role.
Data Stream
Data Stream is an important concept in ES, which has the following characteristics:
- Streaming writes. Data Stream is a data set written in stream rather than in block.
- Append-only writes. Data Stream updates data via append writes and does not require modifying existing data.
- Timestamp. A timestamp is given to each new piece of data to record when it was created.
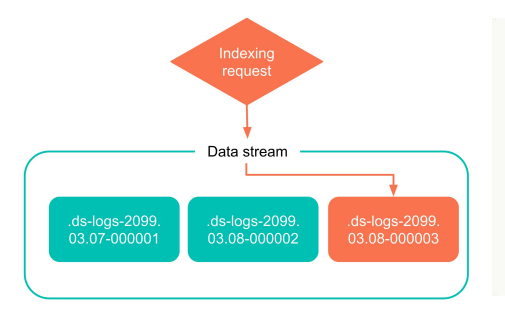
- Multiple indexes: In ES, every piece of data resides in an Index. The data stream is a higher level concept, one data stream may compose of many indexes, which are generated according to different rules. However, only the latest index is writable, while the historical indexes are read-only.
Log data is a typical type of data steam. It is append-only and also has to be timestamped. The user will generate new indexes by different dimensions, such as day or others.
The scheme below is a simple example of index creation for a data stream. In the process of using the data stream, ES will write directly to the latest index. As more data is generated, this index will eventually become an old, read-only index.
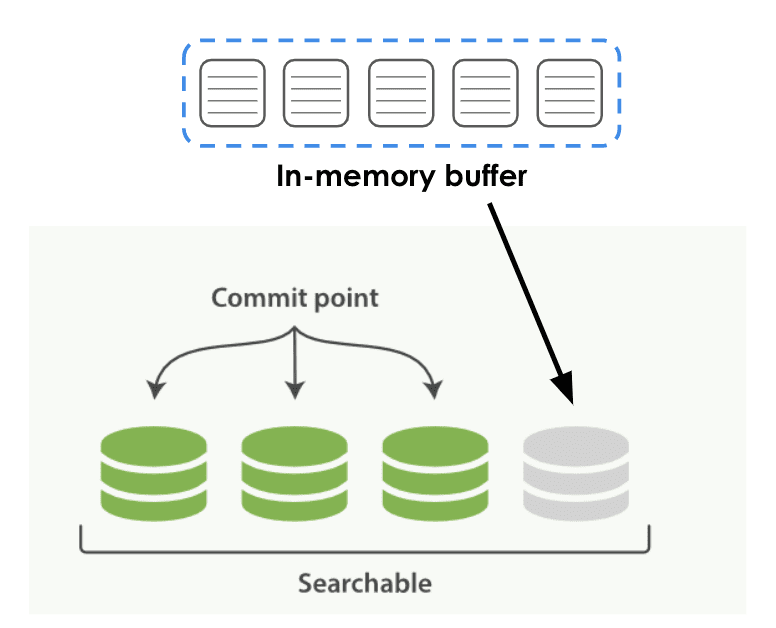
The following graph illustrates writing data to the ES, including two phases.
- Stage 1: the data is first written to the In-memory buffer.
- Stage 2: The buffer will fall to the local disk according to certain rules and time, which is shown as green in the graph (persistent data), known as segment in ES.
There may be some time lag in this process, and the newly created segment cannot be searched if a query is triggered during the persistence process. Once the segment is persisted, it can be searched by the upper-level query engine immediately.
Index Lifecycle Management
Index Lifecycle Management (ILM), is the lifecycle management of an index, and ILM defines the lifecycle of an index as 5 phases.
- Hot data: needs to be updated or queried frequently.
- Warm data: no longer updated, but is still frequently queried.
- Cold data: no longer updated and is queried less frequently.
- Frozen data: no longer updated and hardly ever queried. It is safe to put this kind of data in a relatively low-speed and cheap storage medium.
- Deleted data: no longer needed and can be safely deleted. All ES index data will eventually go through these stages, users can manage their data by setting different ILM policies.
Node Role
In ES, each deployment node will have a Node Role. Different roles, such as master, data, ingest, etc., will be assigned to each ES node. Users can combine the Node Roles, and the different lifecycle phases mentioned above, for data management.
The data node has different stages, and it can be a node that stores hot data, warm data, cold data, or even extremely cold data. The node will be assigned different roles based on its tasks, and different nodes are sometimes configured with different hardware depending on roles.
For example, hot data nodes need to be configured with high-performance CPUs or disks, for nodes with warm and cold data, as these data are queried less frequently, the requirement for hardware is not necessarily high for some computing resources.
Node roles are defined based on different stages of the data lifecycle.** It is important to note that each ES node can have multiple roles, and these roles do not need to have a one-to-one relationship**. Here's an example where node.roles is configured in the ES YAML file. You can also configure multiple roles for the node that it should have.
node.roles: ["data_hot", "data_content"]
Lifecycle Policy
After understanding the concepts of Data Stream, Index Lifecycle Management, and Node Role, you can customize lifecycle policies for your data.
Based on the different dimensions of index characteristics defined in the policy, such as the size of the index, the number of documents in the index, and the time when the index was created, ES can automatically help users roll over data from one lifecycle stage to another, which is known as rollover in ES.
For example, the user can define features based on the size of the index and roll over the hot data to the warm data, or roll over the warm data to the cold data according to some other rules. ES can do the job automatically, while the lifecycle policy needs to be defined by the user.
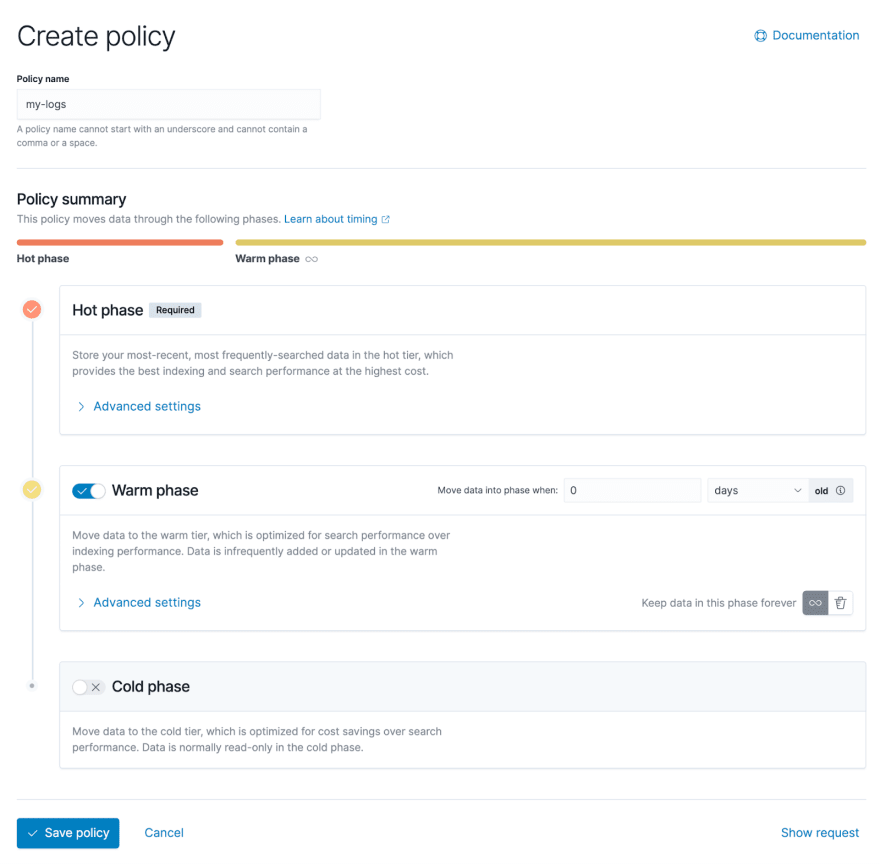
The screenshot below shows Kibana's administration interface, which allows users to graphically configure lifecycle policies. You can see that there are three phases:hot data, warm data, and cold data.
Expanding the advanced settings, you can see more details about configuration policies based on different characteristics,which is listed on the right side of the screenshot below.
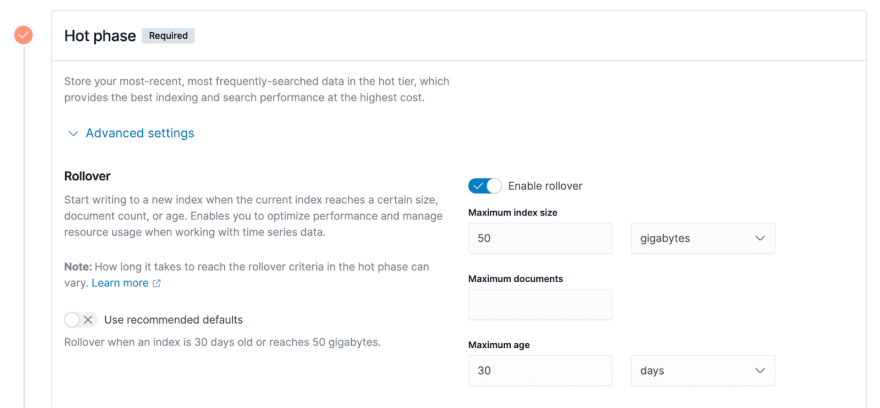
Maximum index size. Take an example of 50 GB in the above screenshot. It means that data will be rolled from the hot data phase to the warm data phase when the size of the index exceeds 50GB.
Maximum documents. The basic storage unit of ES index is document, and the user data is written to ES in the form of documents. Thus, the number of documents is a measurable indicator.
Maximum age. As an example of 30 days, i.e., an index has been created for 30 days, it will trigger the rollover of the hot data to the warm data phase as mentioned previously.
However, using Elasticsearch directly on object storage can cause poor write performance and compatibility and other issues. Thus, companies that also want to balance query performance are starting to look for solutions on the cloud. Under this context, JuiceFS is increasingly being used in data tiering architectures.
2 practice of ES + JuiceFS
Step 1: Prepare multiple types of nodes and assign different roles. Each ES node can be assigned different roles, such as storing hot data, warm data, cold data, etc. Users need to prepare different types of nodes to match the needs of different roles.
Step 2: Mount the JuiceFS file system. Generally users use JuiceFS for warm and cold data storage, users need to mount the JuiceFS file system locally on the ES warm data node or cold data node. The user can configure the mount point into ES through symbolic links or other means to make ES think that its data is stored in a local directory, but this directory is actually a JuiceFS file system.
Step 3: Create a lifecycle policy. This needs to be customized by each user, either through the ES API or through Kibana, which provides some relatively easy ways to create and manage lifecycle policies.
Step 4: Set a lifecycle policy for the index. After creating a lifecycle policy, you need to apply the policy to the index, that is, you need to set the policy you just created for the index. You can do this by using index templates, which can be created in Kibana, or explicitly configured through the API via index.lifycycle.name.
Here are a few tips.
Tip 1: The number of copies (replicas) of Warm or Cold nodes can be set to 1. All data is placed on JuiceFS, eventually uploaded to the underlying object storage, so the reliability of the data is high enough. Accordingly, the number of copies can be reduced on the ES side to save storage space.
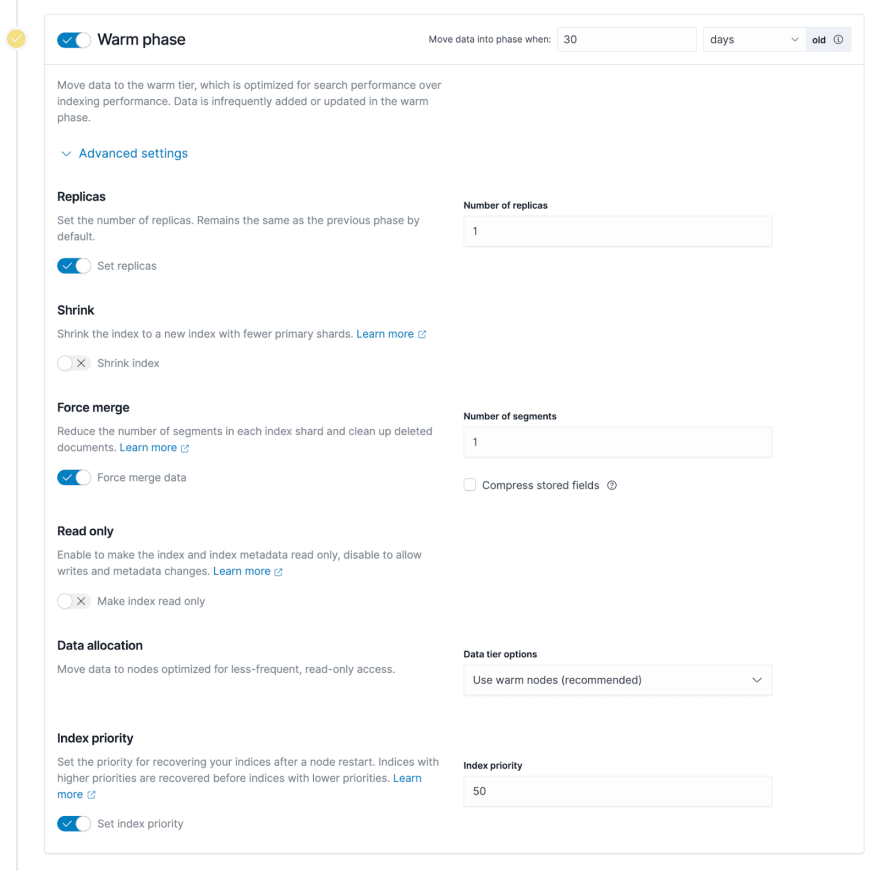
Tip 2: Turning on Force merge may cause constant CPU usage on nodes, so turn it off if appropriate. When moving from hot data to warm data, ES will merge all the underlying segments corresponding to the hot data index. If Force merge is enabled, ES will first merge these segments and then store them in the underlying system of warm data. However, merging segments is a very CPU-consuming process. If the data node of warm data also needs to carry some query requests, you can turn off this function as appropriate, that is, keep the data intact and write it to the underlying storage directly.
Tip 3: The index of Warm or Cold phase can be set to read-only. When indexing warm and cold data phases, we can basically assume that the data is read-only and the indexes will not be modified. Setting the index to read-only can reduce some resource usage on the warm and cold data nodes, you can then scale down these nodes and save some hardware resources.
From Juicedata/JuiceFS ! (0ᴗ0✿)
...