

 800+ IT
News
als RSS Feed abonnieren
800+ IT
News
als RSS Feed abonnieren📚 Testing SurrealDB
💡 Newskategorie: Programmierung
🔗 Quelle: dev.to
A word on SurrealDB
When an application runs on embedded devices, with the model "off-line first", you want to use your embedded (local) database first. When the user has access to the internet, you can sync with a remote database. One can use SQLite, a single file database, but it may be hard to synchronise with a backend. Here comes SurrealDB into play. It is a lightweight cloud-native database that claims to synchronise easily to a backend.
SurrealDB is essentially a key/value ACID-compliant database. It can run in memory or with local persistence, or with a remote connection. Redis is this kind of in-memory database mainly used for caching, for PubSub and streams (queue-like). SurrealDB is different; you can run it from the backend or in the browser. It offers a DSL very close to SQL and allows you to write Javascript functions.
By default, it is schemaless; you can insert any key/value. When you want more control, you can turn a table into a schemafull table.
If you run the server locally, you need to start a server. It can also be run "serverless", meaning that you reach a service in the cloud. By default, it points to https://cloud.surrealdb.com. The server provides a REST API and a unique endpoint at "/sql".
All you need to do is send POST requests to the endpoint with the query in the body.
Websockets aren't documented at the moment, nor how to secure the data.
It is also worth noting that there are some functions to deal with GeoJSON data. It is an important topic as many apps that deal with geolocation are embedded apps. However, spatial indexing doesn't seem to be implemented (yet?) (cf PostGis using GIST).
A word on SurrealDB
Start a local SurrealDB server
Interact with the server
Schemaless tables
- First CREATE
- Transaction
- Timestamps
- Record links
- Query nested records without "join"
- Type functions
- Parameters and subqueries
Graph connections
- Array of linked records
- Connections
Schemafull Tables
-
First case 3 tables
- Prevent bad insertions
- Insert into a nested array
- Nested query without "join"
- Second case 2 tables
Events
Register User
Elixir package SurrealEx setup
Start a local SurrealDB server
You can run a Docker image. We pass the super user credentials and run an in-memory database with:
docker run --rm -p 8000:8000 surrealdb/surrealdb:latest start \
--log debug --user root --pass root memory
Alternatively, you install SurrealDB and run:
surreal start --log debug --user root --pass root memory
You should get the following prompt:
.d8888b. 888 8888888b. 888888b.
d88P Y88b 888 888 'Y88b 888 '88b
Y88b. 888 888 888 888 .88P
'Y888b. 888 888 888d888 888d888 .d88b. 8888b. 888 888 888 8888888K.
'Y88b. 888 888 888P' 888P' d8P Y8b '88b 888 888 888 888 'Y88b
'888 888 888 888 888 88888888 .d888888 888 888 888 888 888
Y88b d88P Y88b 888 888 888 Y8b. 888 888 888 888 .d88P 888 d88P
'Y8888P' 'Y88888 888 888 'Y8888 'Y888888 888 8888888P' 8888888P'
[2023-02-18 20:12:12] INFO surrealdb::iam Root authentication is enabled
[2023-02-18 20:12:12] INFO surrealdb::iam Root username is 'root'
[2023-02-18 20:12:12] INFO surrealdb::dbs Database strict mode is disabled
[2023-02-18 20:12:12] INFO surrealdb::kvs Starting kvs store in memory
[2023-02-18 20:12:12] INFO surrealdb::kvs Started kvs store in memory
[2023-02-18 20:12:12] INFO surrealdb::net Starting web server on 0.0.0.0:8000
[2023-02-18 20:12:12] INFO surrealdb::net Started web server on 0.0.0.0:8000
Interact with the server
cURL
You can send POST requests via cURL with a payload, the two headers (NS for namespace, DB for database) and a BASIC Authentication to the endpoint:
data = "create tab:john name='john'"
curl -k -L -s --compressed POST \
--header "Accept: application/json" \
--header "NS: test" \
--header "DB: test" \
--user "root:root" \
--data "${DATA}" \
http://localhost:8000/sql
SurrealDB CLI
If you installed SurrealDB, you can use CLI where you set the namespace and the database name, and the basic authentication of the super-user. You can then type directly your queries:
$ surreal sql --conn http://localhost:8000 \
--user root --pass root --ns testns --db testdb
> INFO FOR tb;
[{"time": "1.47255ms", "status": "OK", ...]
> CREATE ...
HTTP client
You can use any HTTP client to POST queries, again with the correct headers and basic authentication.
For example, in Elixir with the HTTP client HTTPoison:
url = "http://localhost:8000/sql"
headers = [
{"accept", "application/json"},
{"Content-Type", "application/json"},
{"NS", "testns"},
{"DB", "testdb"}
]
auth = [hackney: [basic_auth: {"root", "root"}]]
query = "create table:test set name='hello world';"
HTTPoison.post!(url, query, headers, auth)
|> Map.get(:status_code)
You can get the response:
HTTPoison.post!(url, "select * from test;", headers, auth)
|> Map.get(:body)
|> Jason.decode!()
Schemaless tables
First CREATE
Each individual statement within SurrealDB is run within its own transaction.
Every row is identified relatively to a table. To CREATE a row with the "SurQL" DSL, we pass a table name and possibly a unique id in the format <table>:<id> and SET the body with a list of <key>=<value>.
You can pass the SurQL query into the CLI or to the HTTP client or package.
CREATE dev:nelson SET name = 'nelson', status= 'founder';
[{"time":"4.1355ms","status":"OK","result":[{"id":"dev:nelson","name":"nelson","status":"founder"}]}]
When we pass an id (the :nelson), the transaction can be run only once. When you don't specify the id, SurrealDB will assign one for you. Note that you can now run the CREATE query below multiple times, but you maybe don't want this.
CREATE dev SET name = 'again', status='founder'
[{"id":"dev:kdofs33s4izrt04djc8s","name":"again","status":"founder"}]}]
You can also use INSERT INTO and pass a JSON object (where you can specify the id), or use a more SQL like with INSERT INTO ... VALUES:
INSERT INTO dev {id: 'bob_id', name: 'bob', status: 'trainee' };
INSERT INTO dev (id, name, status, id) VALUES ('mike', 'founder', 'mike');
We check the table:
SELECT * FROM dev;
[{"id":"dev:bob_id","name":"bob","status":"trainee"},
{"id":"dev:kdofs33s4izrt04djc8s","name":"again","status":"founder"},
{"id":"dev:mike","name":"founder","status":"mike"},
{"id":"dev:nelson","name":"nelson","status":"founder"},
{"id":"dev:ssd3lt188dndo0a2afne","name":"again","status":"founder"}]
Transaction
You can use a transaction for a set of changes. You can use CREATE and pass params, or run an INSERT INTO and pass a JSON object.
BEGIN TRANSACTION;
CREATE dev:lucio SET name = 'lucio', status = 'dev';
INSERT INTO dev {name: 'nd', id: 'nd', status: 'trainee'};
COMMIT TRANSACTION;
Multiple inserts
You pass an array of tuples. You can pass an id, or let Surreal do it for you if you don't need to retrieve them immediately.
INSERT INTO dev [{name: 'Amy'}, {name: 'Mary', id: 'Mary'}];
The first row has an auto-assigned id:
[{"id":"dev:mdfeausb4gata00vcxav","name":"Amy"},
{"id":"dev:Mary","name":"Mary"}]
This is how you can serialize into SurrealDB a CSV file for example:
INSERT INTO users (id, name) VALUES ('a','a'),('b','b'),...
Timestamps
We can use futures for this. It is a value that will be dynamically computed on every access to the record.
For example, we create a record with an id, a (fixed) "created_at" field, and a future field "updated_at":
CREATE dev:1 SET
name='one',
created_at=time::now(),
updated_at=<future>{time::now()};
UPDATE dev:1 SET name='new one';
[{"created_at":"2023-02-21T20:42:07.978776Z",
"id":"dev:1","name":"new one",
"updated_at":"2023-02-21T20:42:36.468812Z"}]}]
Record links
You can pass a nested object with the dot "." format. Note how we can pass record links of the "developper" table into the "webapp" table.
CREATE app_table:surreal SET
app_name = 'surrealistic.com',
agency.team = [dev:nelson, dev:lucio, dev:nd],
agency.name = 'dwyl.com';
You can equivalently pass the data in JSON format:
INSERT INTO app_table {
id: 'unreal',
app_name: 'unreal',
agency: {
name: 'dwyl.com',
team: [dev:nelson, dev:lucio]
}
};
UPDATE app_table:unreal SET app_name='unreal.com';
Query nested records without "join"
We can get linked data without joins with the dot . notation:
SELECT agency.team.*.name AS team, agency.team.*.status AS status
FROM app_table:surreal;
[{"team":["nelson","lucio","nd"],
"status":["founder","dev","trainee"]}}}]
We can get the name for the devs with status 'dev' per agency by using a nested WHERE:
SELECT app_name,agency.team[WHERE status='dev'].name AS dev
FROM app_table
WHERE agency.name = 'dwyl.com';
[{"app_name": "surrealistic.com", "dev": "lucio"},
{"app_name": "unreal.com", "dev": "lucio"}]
Aggregation query
Return the number of devs in the team for the app_table row "unreal" with array functions.
SELECT * from array::len(app_table:unreal.agency.team);
[{"time":"218.125µs","status":"OK","result":[2]}]
You can also use count(). Return the number of developpers and their names per project:
SELECT
app_name,
agency.name AS agency,
agency.team.*.name AS members,
count(agency.team) AS team_count
FROM app_table;
[{"agency":"dwyl.com","app_name":"surrealistic.com","members":["nelson","lucio","nd"],"team_count":3},
{"agency":"dwyl.com","app_name":"unreal.com","members":["nelson","lucio"],"team_count":2}]
Type functions
You can use type functions that converts a string into the desired type:
SELECT count() AS total, app_name
FROM type::table('app_table')
GROUP BY app_table;
[{"app_name":"surrealistic.com","total":2}]
You can use the generic type:thing and pass the object and identifier:
SELECT * FROM type::thing('app_table', 'unreal');
[{"agency":{"name":"dwyl.com","team":["dev:nelson","dev:lucio"]},
"app_name":"unreal.com","id":"app_table:unreal"}]
Parameters and subqueries
We can run queries with parameters. Given a webapp, get the names of the team members with status "dev":
LET $status='dev'
LET $dev_team = (SELECT agency.team[WHERE status=$status] FROM app_table:unreal);
SELECT name, status from $dev_team;
[{"name": "lucio", "status": "dev"}]
Graph connections
Suppose we have a 1-n relation between agencies and webapps, and a 1-n relation between agencies and devs. In a conventional DB, we would have a foreign key "agency_id" in the table Webapp (Webapp belongs_to Agency), and a foreign key "agency_id" in the Dev table (Dev belongs_to Agency).
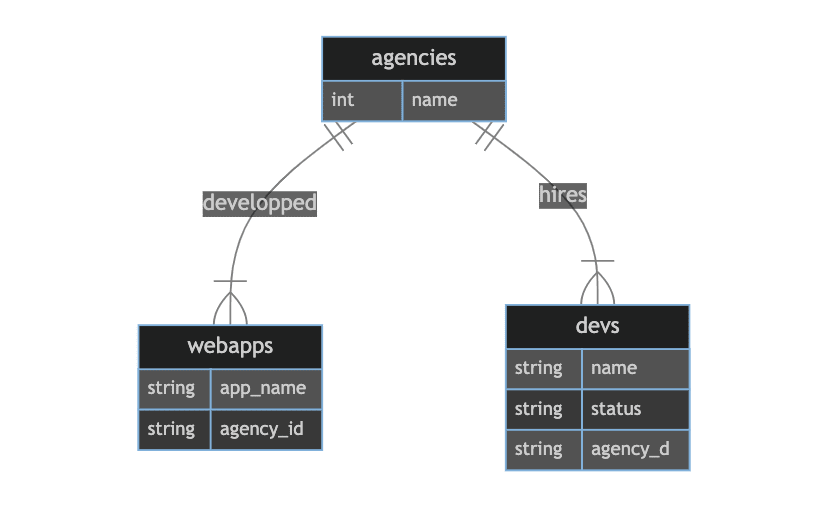
With SurrealDB, we can use 2 approaches:
- set an array of [webapp_ids] and an array of [dev_ids] as fields of the table Agency,
- or set connections between the nodes.
Array of linked records
The ERD of the first approach is shown below:
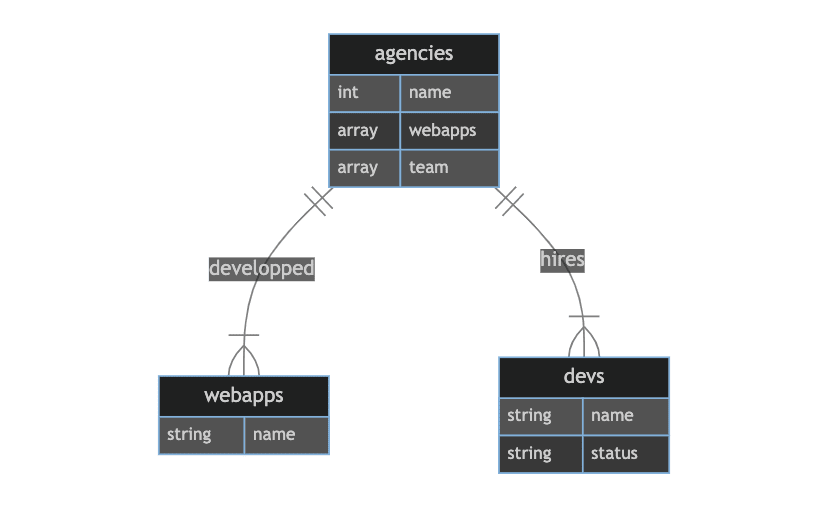
We added a field "team" and webapps which respectively stores all the references to devs employed and to webapps developed by an agency.
BEGIN TRANSACTION;
create webapp:app1 set name = 'app1';
create webapp:app2 set name = 'app2';
create webapp:app3 set name = 'app3';
create developper:nelson set name = 'nelson', status = 'founder';
create developper:nd set name = 'nd', status = 'trainee';
create developper:lucio set name = 'lucio', status = 'dev';
create agency:dwyl1 set name = 'dwyl', project = [], team = [];
create agency:unreal1 set name = 'unreal', project = [], team = [];
update agency:dwyl1 set projects += [webapp:1, webapp:3];
update agency:unreal1 set projects += [webapp:2];
update agency:dwyl1 set team += [developper:nelson, developper:lucio];
update agency:unreal1 set team += [developper:nd];
COMMIT TRANSACTION;
We can get the team members name per agency (by omitting the id) since we have a relation 1-n with record links:
SELECT name AS company, team.*.name AS employees FROM agency:dwyl1;
[{"company":"dwyl","employees":["nelson","lucio"]}]}]
Conversely, find the agency for which a dev works. We used the CONTAINS operator.
SELECT name AS company FROM agency WHERE team CONTAINS developper:nd;
[{"company":"unreal"}]}
Connections
The second approach with connections is shown below. We setup 2 connections with the 2 verbs "works_for" and "developped". This will generate 2 other tables.
[dev:id]->works_for->[agency:id][agency:id]->developped->[webapp:id]
The order is not important as in the first case, it is a 1-1, and a 1-n in the second case. It turns out that we can reverse the links are we will see. A connection is coded with RELATE @from->verb->@to

BEGIN TRANSACTION;
CREATE agency:dwyl2 SET name = 'dwyl';
CREATE agency:unreal2 SET name = 'unreal';
RELATE developper:lucio->works_for->agency:dwyl2 CONTENT {owner: false, created_at: time::now()};
RELATE developper:nelson-> works_for->agency:dwyl2 CONTENT {owner: true, created_at: time::now()};
RELATE developper:nd->works_for->agency:unreal2 CONTENT {owner: true, created_at: time::now()};
RELATE agency:dwyl2->developped->webapp:app1;
RELATE agency:unreal2->developped->webapp:app2;
RELATE agency:dwyl2->developped->webapp:app3;
COMMIT TRANSACTION;
We can take a peek at the association-table "works_for":
SELECT * FROM developped;
We have an association [dev:id]->works_for->[agency:id]. We can query for the agency.name given a dev:id:
SELECT name, ->works_for->agency.name AS employer FROM developper:nelson;
[{"employer":["dwyl"],"name":"nelson"}]
We now want all the devs working for a particular agency. We just revert the relation: get all dev:id from agency:id:
SELECT name, <-works_for<-developper.name AS employees FROM agency:dwyl2;
[{"employees":["nelson","lucio"],"name":"dwyl"}]
Similarly, we can check the webapps name developped by an agency with the association with [agency:id]->developped->[webapp:id].
SELECT ->developped->webapp.name AS agency FROM agency:dwyl2;
[{"agency":["app1","app3"]}]
To query the agency which developped a given webapp, we reverse the query:
SELECT <-developped<-agency.name AS agency FROM webapp:app2;
[{"employees":["nelson","lucio"],"name":"dwyl"}]
We can run subqueries if we want the devs that worked on a given webapp:
LET $agency=(SELECT <-developped<-agency.id AS id FROM webapp:app1);
SELECT <-works_for<-developper.name AS employees FROM $agency;
[{"employees":[["nelson","lucio"]]}]
Schemafull tables
If we want to enforce a fixed struct, we can define a schema with DEFINE TABLE ... SCHEMAFULL.
We will check this enforcement below.
The ERD shows a one_to_many_through relation with 3 tables. Apps has many users, and uses has one details. We set a 1-N relation between app and users, and 1-1 between users and details. We elaborate ith 2 examples:
- one with 3 tables where we pass an array of references (apps<-[users:id]) and a reference to another table (users <- details:id),
- and one with 2 tables where we pass an array of references (apps<-[users:id]) and an object (users.details{}) that mirrors the thrid table.
How to pass an array of references?
Since we will have nested data in each table, we create a field that should be an array of references to the other table. For this:
- create a field say
teamof typearrayin the table "apps", - and declare the
team.*of typerecord(users)which are references to rows of the table "users".
For the table users, we have a 1-1 relation with the table details. In the first case mentionned above, we add a field of type record(details). In the second case, we declare a field of TYPE object and declare the nested fields in the table "users" that mirror the "details" table that is not used.
We also use INDEX to enforce uniqueness. We also showcased field constraints and default values (with VALUE $value)
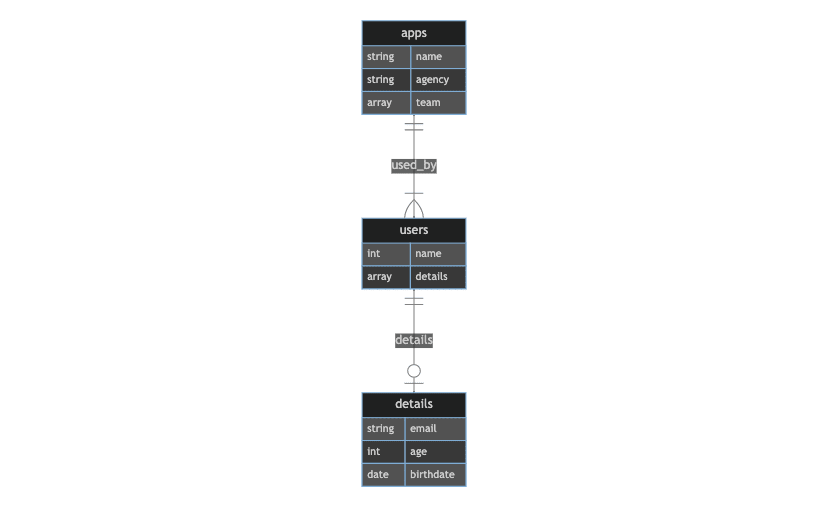
First case 3 tables
Conn.sql("
BEGIN TRANSACTION;
DEFINE TABLE details SCHEMAFULL;
DEFINE FIELD email ON details TYPE string;
DEFINE FIELD age ON details type int ASSERT is::numeric($value) and $value>18;
DEFINE FIELD birthdate ON details TYPE string;
DEFINE TABLE users SCHEMAFUL;
DEFINE FIELD name ON users type string;
DEFINE FIELD details ON users TYPE record(details);
DEFINE INDEX users ON TABLE users COLUMNS name UNIQUE;
DEFINE TABLE apps SCHEMAFULL;
DEFINE FIELD name ON apps TYPE string;
DEFINE FIELD agency ON apps TYPE string VALUE $value OR 'dwyl';
DEFINE FIELD team ON apps TYPE array;
DEFINE FIELD team.* ON apps TYPE record(users);
DEFINE INDEX name ON TABLE apps COLUMNS name UNIQUE;
COMMIT TRANSACTION;
")
We can INSERT INTO (and set the :id), or CREATE SET. We can pass nested links. SurrealDB understands dates.
BEGIN TRANSACTION;
INSERT INTO details {id: 'john', email: 'john@com', age: 20, birthdate: '2023-03-01'};
INSERT INTO users {name: 'john', id: 'john', details: details:john};
CREATE details:lucio SET email='lucio@com', age = 20, birthdate = '2023-03-01';
INSERT INTO users { id: 'lucio', name: 'lucio', details: details:lucio};
INSERT INTO users {name: 'nelson', id: 'nelson'};
INSERT INTO apps {id: 'test', agency: 'dwyl', team: []};
COMMIT TRANSACTION;
SELECT * FROM apps;
Prevent bad insertions
Let's insert a "bad" record into the "details" table: we get an error:
INSERT INTO details {gender: 'f', occupation: 'eng', age: 'twenty', id: 'wrong'};
[{"time":"427.541µs","status":"ERR",
"detail":"Found 0 for field `age`, with record `details:wrong`,
but field must conform to: is::numeric($value) AND $value > 18"}]
Insert into a nested array
Let's create a new "dev" and add him as a team member: we use array:concat (doc) or simply +=.
Before:
SELECT team from apps:test;
Let's update and check if only filtered data of type "users" is accepted:
UPDATE apps:test SET team += [users:nelson, users:lucio, 'ok'], bad = 'input';
After:
SELECT team FROM apps:test;
Nested query without "join"
Let's select the names of the users for all apps developped by the agency "dwyl":
SELECT team.*.name FROM apps WHERE agency = 'dwyl'
[{"team":{"name":["nelson","lucio"]}}]
Second case: 2 tables
Instead of defining a third table "details", we pass an object of TYPE object as a field of the table "users", and define the fields as nested attributes (details.owner for example). Since we defined a SCHEMAFULL table, the input is still filtered. For example, we can't pass an extra attribute in the "details" object on the talbe "users".
BEGIN TRANSACTION;
DEFINE TABLE users1 SCHEMAFUL;
DEFINE FIELD name ON users1 type string;
DEFINE FIELD details ON users1 TYPE object;
DEFINE FIELD details.age ON users1 TYPE int;
DEFINE FIELD details.owner ON users1 TYPE bool;
DEFINE INDEX users1 ON TABLE users1 COLUMNS name UNIQUE;
DEFINE TABLE apps1 SCHEMAFULL;
DEFINE FIELD name ON apps1 TYPE string;
DEFINE FIELD agency ON apps1 TYPE string;
DEFINE FIELD team ON apps1 TYPE array;
DEFINE FIELD team.* ON apps1 TYPE record(users1);
DEFINE INDEX name ON TABLE apps1 COLUMNS name UNIQUE;
COMMIT TRANSACTION;
INSERT INTO users1 {
id: 1,
name: 1,
details: {
age: 20,
owner: false,
test1: 'bad'
}
};
INSERT INTO users1 {
id: 2,
name: 2,
details: {
age: 20,
owner: true
}
};
INSERT INTO apps1 {
name: 'app1',
agency: 'surreal',
team: [users1:1, users1:2, 'toto']
};
Events
Let's create an event query example. When we change a field, say the birthdate of the table details, we want to create a new table that records this new date. We can do this with DEFINE EVENT:
DEFINE EVENT passed_birthdates ON TABLE details
WHEN $before.birthdate < $after.birthdate
THEN (
CREATE passed_birthdates SET birthdate = $after.birthdate
);
We update 2 rows of the table "details" where we change the birthdate:
BEGIN TRANSACTION;
UPDATE details:john SET birthdate='2023-03-02';
UPDATE details:lucio SET birthdate='2023-03-02';
COMMIT TRANSACTION;
We check that the change in the field triggered the action to create a new table where the record has the field with value the new date.
SELECT * FROM passed_birthdates;
We have two events:
[{"time":"213.625µs","status":"OK","result":
[{"birthdate":"\"2023-03-02T00:00:00Z\"","id":"passed_birthdates:6i4cdsmue06v2rbfiwdt"},
{"birthdate":"\"2023-03-02T00:00:00Z\"","id":"passed_birthdates:i5ly5nxb1y3lo4knzkms"}]}]
Register User
Provides a registration via JWT
You may use the helpful package SurrealEx (see Elixir setup)
Elixir package SurrealEx setup
A Livebook to experiment:![]()
You have two ways to setup the package SurrealEx. Firstly, you setup a config file as below.
#config.exs
import Config
config :surreal_ex, Conn,
interface: :http,
uri: "http://localhost:8000",
ns: "testns",
db: "testdb",
user: "root",
pass: "root"
For Livebook, put the file below in your root directory, and add the key config_path: "config.exs" in the Mix.install of the Livebook.
Mix.install(
[{:surreal_ex, "~> 0.2.0"}],
config_path: "config.exs"
)
You can alternatively use the module SurrealEx.Config. Let's define a module Conn to wrap the config.
defmodule Conn do
@config [
interface: :http,
uri: "http://localhost:8000",
ns: "test",
db: "test",
user: "root",
pass: "root"
]
use SurrealEx.Conn
def setup do
@config
|> SurrealEx.Config.for_http()
|> SurrealEx.Config.set_config_pid()
end
end
You describe the config: uri, (namespace, database) and basic auth, and pass it to the Conn module which uses the SurrealEx.Conn behaviour.
You run the setup:
Conn.setup()
cfg = SurrealEx.Config.get_config(Conn)
We can now use SurrealDB. Every query above can be run when wrapped with Conn.sql(query).
IF you register users, you get a token and can secure the query with Conn.sql(query, token).
There are other interesting routines with SurrealEx, in particular the SurrealEx.HTTP that allows to pipe queries.