

 800+ IT
News
als RSS Feed abonnieren
800+ IT
News
als RSS Feed abonnieren📚 Improving Hebrew Q&A Models via Prompting
💡 Newskategorie: AI Nachrichten
🔗 Quelle: towardsdatascience.com
Improving Hebrew Q&A Models via Intelligent Prompting

Hi all,
I am sharing a short project I worked on that involves improving the performance of the text-davinci-003 model by OpenAI using intelligent prompting. I will start by saying that this work is inspired by the excellent video tutorials by James Briggs — (specifically this one — https://youtu.be/dRUIGgNBvVk) and much of the code I used is taken from his examples as well.
The outline of this article is as follows:
- Intro — Unique and Proprietary data in Large Language Models (LLMs)
- Problem Statement — Answering Questions in Hebrew
- Solution Suggestion — Prompting & Querying
- Experiment — Question Answering in Hebrew
- Conclusions
A Google Colab notebook with the complete code is here — https://colab.research.google.com/drive/1_UqPHGPW1yLf3O_BOySRjf3bWqMe6A4H#scrollTo=4DY7XgilIr-H
Part 1. Problem Statement — Unique and Proprietary data in Large Language Models
The main official language in Israel is Hebrew, and as an Israeli, I am interested in improving the performance of large language models in Hebrew. It is a widely known fact that the performance of ChatGPT in Hebrew could be better relative to its performance in English, despite recent improvements. In this article, though, Hebrew is only an allegory to a source of data that is under-represented in a large language model and this article is going to deal with an attempt to assist an LLM in yielding useful results which are based on such data.
One option, which was common before the era of very large language models, was to perform additional training on the model with the new data/task. When the models were at a scale of millions of parameters this option was a viable approach for many people and use cases and was achievable using common consumer hardware.
In the past several years there has been an explosion in model sizes for large language models, which nowadays reach hundreds of billions of parameters. On the other hand, consumer hardware has not seen such a massive efficiency explosion. Thus, the option for fine-tuning these models has been taken off the table for most users and organizations.
ChatGPT is widely known already and it achieves remarkable performance on many tasks and is proving to be an invaluable AI assistant. Yet still, if I want to use this technology to assist a person speaking in a rare language, or to assist a company with proprietary data which is not available online — chances are that ChatGPT will fail for obvious reasons of not seeing the data beforehand. So how do we make use of special/proprietary data in these models, without requiring millions of dollars for training using special hardware? One option is prompting via querying, which we will explore today.
Part 2. Problem Statement — Answering Questions in Hebrew
We will use the OpenAI API to answer three questions in Hebrew, which were inspired by the SQuAD dataset and translated into Hebrew. The following code snippet shows the questions, expected answers, and English translations.
questions_answers = [
{'subject': 'אוסטרליה',
'subject_translation': 'Australia',
'question': "איזו עיר בויקטוריה נחשבת לבירת הספורט של אוסטרליה?",
'answer': "מלבורן",
'question_translation': "Which city in Victoria is considered the sporting capital of Australia?",
'answer_translation': "Melbourne"},
{'subject': 'אוניברסיטה',
'subject_translation': 'University',
'question': "איזה נהר ממוקם בקרבת אוניברסיטת הארווארד?",
'answer': "נהר צ'ארלס",
'question_translation': "Which river is located in the vicinity of Harvard University?",
'answer_translation': "Charles River"},
{'subject': 'המוות השחור',
'subject_translation': 'The black plague',
'question': "כמה אנשים ברחבי העולם נספו בעקבות המוות השחור?",
'answer': "בין 75 ל200 מיליון איש",
'question_translation': "How many people in the world died from the black plague?",
'answer_translation': "Between 75 and 200 million"},
]
Disclaimer — the recent version of ChatGPT proves to yield very good answers for these queries (in Hebrew). The point of this article is not to “compete” with it, but rather to show a solution to a problem that might arise with other models/data.
We will use the text-davinci-003 model to answer the questions using this code, which will call the OpenAI API:
from googletrans import Translator
import openai
def complete(prompt):
# query text-davinci-003
res = openai.Completion.create(
engine='text-davinci-003',
prompt=prompt,
temperature=0,
max_tokens=400,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=None
)
return res['choices'][0]['text'].strip()
def print_question_answer(question, query, expected_answer, question_translation, expected_answer_translation):
translator = Translator()
answer = complete(query)
print(f'Question: {question}\n' \
f'Question (translation): {question_translation}\n' \
f'Answer: {answer}\n' \
f'Answer (translation): {translator.translate(answer).text}\n' \
f'Expected Answer: {expected_answer}\n' \
f'Expected Answer (translation): {expected_answer_translation}'
)
for i, qa_dct in enumerate(questions_answers):
print(f'####################')
print(f'Question #{i + 1}:')
print_question_answer(qa_dct['question'],
qa_dct['question'],
qa_dct['answer'],
qa_dct['question_translation'],
qa_dct['answer_translation'],
)
Output:
####################
Question #1:
Question: איזו עיר בויקטוריה נחשבת לבירת הספורט של אוסטרליה?
Question (translation): Which city in Victoria is considered the sporting capital of Australia?
Answer: סידני.
Answer (translation): Sydney.
Expected Answer: מלבורן
Expected Answer (translation): Melbourne
####################
Question #2:
Question: איזה נהר ממוקם בקרבת אוניברסיטת הארווארד?
Question (translation): Which river is located in the vicinity of Harvard University?
Answer: הנהר הקרוב ביותר לאוניברסיטת הארווארד הוא נהר הקונגו.
Answer (translation): The closest river to Harvard University is the Congo River.
Expected Answer: נהר צ'ארלס
Expected Answer (translation): Charles River
####################
Question #3:
Question: כמה אנשים ברחבי העולם נספו בעקבות המוות השחור?
Question (translation): How many people in the world died from the black plague?
Answer: בעקבות המוות השחור של ג'ורג' פלאי, הפגנו אלפי אנשים ברחבי העולם בכדי להגיב לפעולות הפולישיות של המשטרה האמריקאית. אלפי אנשים הפגינו בערים בכל הארצות האמריקאיות, כמו ג'קסוןביל, ניו יורק, לוס אנג'לס, פילדלפיה, אתרוג, אוסטין, סנט לואיס, אוסטין, אינדיאנה, מישיגן, אורלנדו, קליפורניה, אוהיו, אריזונה, אוקלהומה, ארצות הברית החדשות ועוד. אף אנשים
Answer (translation): Following the black death of George Flay, thousands of people demonstrated around the world to respond to the police actions of the American police. Thousands of people demonstrated in cities in all American countries, such as Jacksonville, New York, Los Angeles, Philadelphia, Etrog, Austin, St. Louis, Austin, Indiana, Michigan, Orlando, California, Ohio, Arizona, Oklahoma, New United States and more . no people
Expected Answer: בין 75 ל200 מיליון איש
Expected Answer (translation): Between 75 and 200 million
We see that text-davinci-003 is very bad at answering these questions out of the box. It gets all three questions wrong and produces some ridiculous answers for the second and third questions.
So the question is asked — how do we solve this? How can we get good answers from text-davinci-003 without having to fine-tune it on a bunch of Hebrew data?
Part 3. Solution Suggestion — Prompting & Querying
As I wrote in the introduction, one way to add information to the LLM without fine-tuning is prompting, which is simply including relevant information in the input to the model. But including relevant information for each query can be a very tedious and time-consuming task, can we automate this?
Of course, we can! Enter prompting via querying. We will take a fairly small dump of Wikipedia in Hebrew, which definitely contains answers to our questions. We will split this dump into lines, embed each of these lines using an embedding model by OpenAI, and insert these embeddings into a vector database called Pinecone DB. Then, for each question we ask the model, we will search the vector database for bits of information that are semantically similar to the question and append them to the model input as additional information. This procedure is shown in figure 1. Hopefully, the model will be able to make use of the provided context and yield correct answers to our questions.
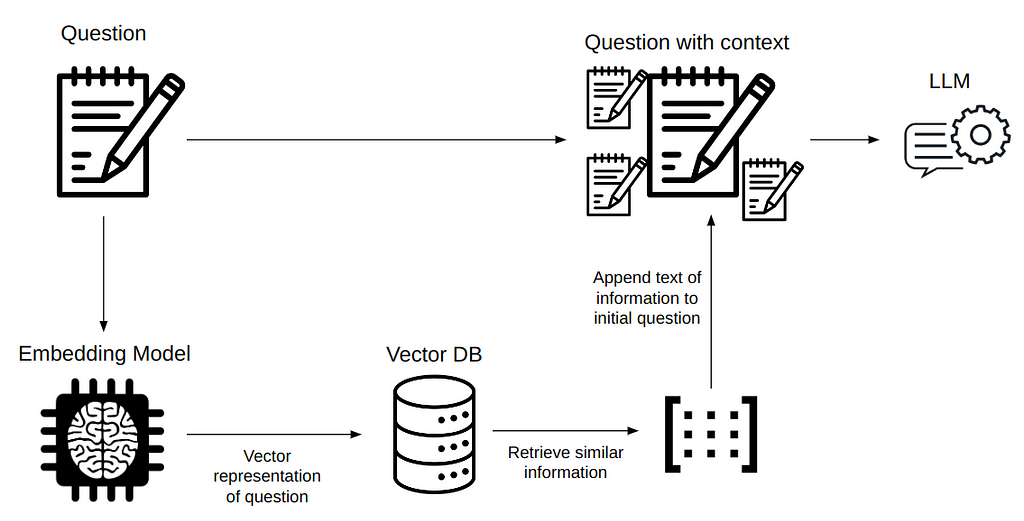
Inspired by Jason Briggs, I will show you a prompt template that will help us generate intelligible prompts to text-davinci-003 and hopefully, make it answer our three previous questions correctly.
Part 4. Experiment — Question Answering in Hebrew
First things first — we need to populate our vector database with relevant information. For this purpose we are going to use a small Hebrew Wikipedia dump which I downloaded from here — https://u.cs.biu.ac.il/~yogo/hebwiki/ (available under a Creative Commons Attribution-ShareAlike 4.0 International License).
with open('/content/drive/MyDrive/Datasets/hebrew_wikipedia/full.txt') as f:
hebrew_wiki = f.readlines()
openai_price_per_1k = 0.00004
n_tokens = sum([len(x) for x in hebrew_wiki])
print(f'This hebrew wikipedia dataset contains {len(hebrew_wiki)} sentences')
print(f'In total it amounts to {n_tokens} tokens')
print(f'With the current pricing of openAI it will cost {(openai_price_per_1k * n_tokens) / 1000:.3f}$ to embed everything')This hebrew wikipedia dataset contains 3833140 sentences
In total it amounts to 380692471 tokens
With the current pricing of openAI it will cost 15.228$ to embed everything
For general information, I calculated how much it will cost to embed the whole Wikipedia dump using the OpenAI API — not too bad! But still, for our purposes we only need specific subjects so we can save some money by choosing more particular sentences to embed:
def get_lines_per_subject(hebrew_wiki, subject, subject_translation):
subject_lines = [(i, x) for i, x in enumerate(hebrew_wiki) if subject in x]
n_tokens = sum([len(x[1]) for x in subject_lines])
print(f'There are {len(subject_lines)} sentences that have the words {subject_translation} in them')
print(f'In total it amounts to {n_tokens} tokens')
print(f'With the current pricing of openAI it will cost {(openai_price_per_1k * n_tokens) / 1000:.3f}$ to embed everything')
return subject_lines
subject_lines = {}
for qa_dct in questions_answers:
subject_lines[qa_dct['subject']] = get_lines_per_subject(hebrew_wiki, qa_dct['subject'], qa_dct['subject_translation'])
There are 7772 sentences that have the words Australia in them
In total it amounts to 1026137 tokens
With the current pricing of openAI it will cost 0.041$ to embed everything
There are 15908 sentences that have the words University in them
In total it amounts to 1904404 tokens
With the current pricing of openAI it will cost 0.076$ to embed everything
There are 160 sentences that have the words The black plague in them
In total it amounts to 19410 tokens
With the current pricing of openAI it will cost 0.001$ to embed everything
That’s better. We are now ready to populate the vector database:
import pinecone
index_name = 'hebrew-wikipedia'
# initialize connection to pinecone (get API key at app.pinecone.io)
pinecone.init(
api_key=pinecone_key,
environment="us-east1-gcp"
)
# check if index already exists (it shouldn't if this is first time)
if index_name not in pinecone.list_indexes():
# if does not exist, create index
pinecone.create_index(
index_name,
dimension=len(res['data'][0]['embedding']),
metric='cosine',
metadata_config={'indexed': ['contains_keywords']}
)
# connect to index
index = pinecone.Index(index_name)
# view index stats
index.describe_index_stats()
We generated a new Pinecone DB index (if it didn’t exist yet). Let’s populate it with our data:
from tqdm.auto import tqdm
import datetime
from time import sleep
embed_model = "text-embedding-ada-002"
batch_size = 32 # how many embeddings we create and insert at once
def insert_into_pinecone(lines, subject):
print(f'Inserting {len(lines)} of subject: {subject} into pinecone')
for i in tqdm(range(0, len(lines), batch_size)):
# find end of batch
i_end = min(len(lines), i+batch_size)
meta_batch = lines[i:i_end]
ids_batch = [str(x[0]) for x in meta_batch]
texts = [x[1] for x in meta_batch]
try:
res = openai.Embedding.create(input=texts, engine=embed_model)
except:
done = False
while not done:
sleep(5)
try:
res = openai.Embedding.create(input=texts, engine=embed_model)
done = True
except:
pass
embeds = [record['embedding'] for record in res['data']]
# cleanup metadata
meta_batch = [{
'contains_keywords': subject,
'text': x,
} for x in texts]
to_upsert = list(zip(ids_batch, embeds, meta_batch))
# upsert to Pinecone
index.upsert(vectors=to_upsert)
for subject, lines in subject_lines.items():
insert_into_pinecone(lines, subject)
Great! We have a populated vector DB. Let’s get the top-2 contexts for the first question (Which city in Victoria is considered the sporting capital of Australia?):
res = openai.Embedding.create(
input=[questions_answers[0]['question']],
engine=embed_model
)
# retrieve from Pinecone
xq = res['data'][0]['embedding']
# get relevant contexts (including the questions)
res = index.query(xq, top_k=2, include_metadata=True)
res
{'matches': [{'id': '2642286',
'metadata': {'contains_keywords': 'אוסטרליה',
'text': 'העיר שוכנת לחופה הצפון-מערבי של '
'אוסטרליה.\n'},
'score': 0.899194837,
'values': []},
{'id': '2282112',
'metadata': {'contains_keywords': 'אוסטרליה',
'text': 'אוסטרלאסיה היה השם של נבחרת הספורטאים '
'מאוסטרליה וניו זילנד שהשתתפה באולימפיאדת '
'לונדון (1908) ובאולימפיאדת סטוקהולם '
'(1912).\n'},
'score': 0.893916488,
'values': []}],
'namespace': ''}We see that the top 2 lines in our vector DB (in terms of cosine similarity to the question’s embedding) are not so helpful. The first line is a very general sentence about Australia and the second indeed talks about sports in Australia, but there is no mention of Melbourne which is the answer we are expecting.
But still, let’s challenge our model and see how it fares now that it has access to additional information in Hebrew. Notice that we instructed our model to answer “I don’t know” if the answer cannot be deduced from the given context.
limit = 3000
def retrieve(query, filter_subjects=None, add_dont_know=False):
res = openai.Embedding.create(
input=[query],
engine=embed_model
)
# retrieve from Pinecone
xq = res['data'][0]['embedding']
# get relevant contexts
res = index.query(xq,
{'contains_keywords': {'$in': filter_subjects}}
if filter_subjects is not None else None,
top_k=100,
include_metadata=True)
contexts = [
x['metadata']['text'] for x in res['matches']
]
# build our prompt with the retrieved contexts included
idk_str = '''. If the question cannot be answered using the
information provided answer with "I don't know"''' if add_dont_know else ''
prompt_start = (
"Answer the question based on the context below." + idk_str + "\n\n" +
"Context:\n"
)
prompt_end = (
f"\n\nQuestion: {query}\nAnswer:"
)
# append contexts until hitting limit
for i in range(1, len(contexts)):
if len("\n\n---\n\n".join(contexts[:i])) >= limit:
prompt = (
prompt_start +
"\n\n---\n\n".join(contexts[:i-1]) +
prompt_end
)
break
elif i == len(contexts)-1:
prompt = (
prompt_start +
"\n\n---\n\n".join(contexts) +
prompt_end
)
return prompt
original_subjects = ['אוסטרליה', 'אוניברסיטה', 'המוות השחור']
for i, qa_dct in enumerate(questions_answers):
print(f'####################')
print(f'Question #{i + 1} with context:')
query_with_contexts = retrieve(qa_dct['question'],
filter_subjects=original_subjects,
add_dont_know=True)
print(f'Length of query with contexts: {len(query_with_contexts)}')
print_question_answer(qa_dct['question'],
query_with_contexts,
qa_dct['answer'],
qa_dct['question_translation'],
qa_dct['answer_translation'],
)
####################
Question #1 with context:
Length of query with contexts: 3207
Question: איזו עיר בויקטוריה נחשבת לבירת הספורט של אוסטרליה?
Question (translation): Which city in Victoria is considered the sporting capital of Australia?
Answer: קנברה
Answer (translation): Canberra
Expected Answer: מלבורן
Expected Answer (translation): Melbourne
####################
Question #2 with context:
Length of query with contexts: 3179
Question: איזה נהר ממוקם בקרבת אוניברסיטת הארווארד?
Question (translation): Which river is located in the vicinity of Harvard University?
Answer: I don't know
Answer (translation): I don't know
Expected Answer: נהר צ'ארלס
Expected Answer (translation): Charles River
####################
Question #3 with context:
Length of query with contexts: 3138
Question: כמה אנשים ברחבי העולם נספו בעקבות המוות השחור?
Question (translation): How many people in the world died from the black plague?
Answer: I don't know.
Answer (translation): I don't know.
Expected Answer: בין 75 ל200 מיליון איש
Expected Answer (translation): Between 75 and 200 million
OK, getting a bit better. The first answer is still wrong. In the second and third answers, we got “I don’t know” which I perceive as a major improvement over getting wrong answers. But still, we want to give current answers, how can we improve on this..?
Let’s add some additional subjects to the vector DB, maybe it didn’t have enough relevant information from which to pull a relevant context.
additional_subjects = [
('מלבורן', 'Melbourne'),
('סידני', 'Sydney'),
('אדלייד', 'Adelaide'),
('הרווארד', 'Harvard'),
("מסצ'וסטס", 'Massachusetts'),
("צ'ארלס", 'Charles'),
('בוסטון', 'Boston'),
('מגפה', 'plague'),
('האבעבועות השחורות', 'smallpox'),
('אבעבועות שחורות', 'smallpox'),
('מונגוליה', 'mongolia')
]
additional_subject_lines = {}
for subject, subject_translation in additional_subjects:
additional_subject_lines[subject] = get_lines_per_subject(hebrew_wiki, subject, subject_translation)
for subject, lines in additional_subject_lines.items():
insert_into_pinecone(lines, subject)
There are 948 sentences that have the words Melbourne in them
In total it amounts to 119669 tokens
With the current pricing of openAI it will cost 0.005$ to embed everything
There are 2812 sentences that have the words Sydney in them
In total it amounts to 347608 tokens
With the current pricing of openAI it will cost 0.014$ to embed everything
There are 213 sentences that have the words Adelaide in them
In total it amounts to 24480 tokens
With the current pricing of openAI it will cost 0.001$ to embed everything
There are 1809 sentences that have the words Harvard in them
In total it amounts to 228918 tokens
With the current pricing of openAI it will cost 0.009$ to embed everything
There are 1476 sentences that have the words Massachusetts in them
In total it amounts to 179227 tokens
With the current pricing of openAI it will cost 0.007$ to embed everything
There are 5025 sentences that have the words Charles in them
In total it amounts to 647501 tokens
With the current pricing of openAI it will cost 0.026$ to embed everything
There are 2912 sentences that have the words Boston in them
In total it amounts to 361337 tokens
With the current pricing of openAI it will cost 0.014$ to embed everything
There are 1007 sentences that have the words plague in them
In total it amounts to 116961 tokens
With the current pricing of openAI it will cost 0.005$ to embed everything
There are 39 sentences that have the words smallpox in them
In total it amounts to 5417 tokens
With the current pricing of openAI it will cost 0.000$ to embed everything
There are 135 sentences that have the words smallpox in them
In total it amounts to 15815 tokens
With the current pricing of openAI it will cost 0.001$ to embed everything
There are 742 sentences that have the words mongolia in them
In total it amounts to 90607 tokens
With the current pricing of openAI it will cost 0.004$ to embed everything
Great, we added richer context (you might even say we are cheating a bit — notice that we added all sentences that contain the words “Melbourne” and “Charles” amongst others, which are the answers to our questions. But it’s just a demonstration!)
for i, qa_dct in enumerate(questions_answers):
print(f'####################')
print(f'Question #{i + 1} with context:')
query_with_contexts = retrieve(qa_dct['question'], add_dont_know=Tue)
print(f'Length of query with contexts: {len(query_with_contexts)}')
print_question_answer(qa_dct['question'],
query_with_contexts,
qa_dct['answer'],
qa_dct['question_translation'],
qa_dct['answer_translation'],
)
####################
Question #1 with context:
Length of query with contexts: 3158
Question: איזו עיר בויקטוריה נחשבת לבירת הספורט של אוסטרליה?
Question (translation): Which city in Victoria is considered the sporting capital of Australia?
Answer: מלבורן
Answer (translation): Melbourne
Expected Answer: מלבורן
Expected Answer (translation): Melbourne
####################
Question #2 with context:
Length of query with contexts: 3106
Question: איזה נהר ממוקם בקרבת אוניברסיטת הארווארד?
Question (translation): Which river is located in the vicinity of Harvard University?
Answer: נהר צ'ארלס
Answer (translation): Charles River
Expected Answer: נהר צ'ארלס
Expected Answer (translation): Charles River
####################
Question #3 with context:
Length of query with contexts: 3203
Question: כמה אנשים ברחבי העולם נספו בעקבות המוות השחור?
Question (translation): How many people in the world died from the black plague?
Answer: לפי הערכות שונות, כ-35 מיליון בני אדם בסין לבדה, ובין 20 ל-25 מיליון בני אדם באירופה.
Answer (translation): According to various estimates, about 35 million people in China alone, and between 20 and 25 million people in Europe.
Expected Answer: בין 75 ל200 מיליון איש
Expected Answer (translation): Between 75 and 200 million
Nice! We have our answers! Although the third answer is still not 100% correct, but way better than “I don’t know” and way better than the initial hallucination.
Part 5. Conclusions
In this article, we have seen how to automatically provide relevant context to an LLM using a vector database in order to improve the model outputs. In this specific case, it might not have been necessary because the performance of ChatGPT (which is available as an API) on Hebrew has improved tremendously and it is able to answer these questions very well out-of-the-box.
Yet still, the point of this article was to introduce this concept, which can be generalized for other purposes such as:
- Using an LLM to analyze proprietary data which is not available online
- Adding a form of explainability to the model, by appending the context which was used to the output of the user (to prove the credibility of the answer).
I hope you enjoyed this article and were motivated to try it for yourself. See you next time!
Elad
References
- Hebrew Wikipedia dump — https://u.cs.biu.ac.il/~yogo/hebwiki/
- SQuAD dataset — https://rajpurkar.github.io/SQuAD-explorer/
- Video tutorial by James Briggs — https://youtu.be/dRUIGgNBvVk
- OpenAI API — https://openai.com/blog/openai-api
- Pinecone DB — https://www.pinecone.io/
Improving Hebrew Q&A Models via Prompting was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
...