

 800+ IT
News
als RSS Feed abonnieren
800+ IT
News
als RSS Feed abonnieren📚 Can ChatGPT compete with domain-specific sentiment analysis Machine Learning Models?
💡 Newskategorie: AI Nachrichten
🔗 Quelle: towardsdatascience.com
A hands-on comparison using ChatGPT and Domain-Specific Model

ChatGPT is a GPT (Generative Pre-trained Transformer) machine learning (ML) tool that has surprised the world. Its breathtaking capabilities impress casual users, professionals, researchers, and even its own creators. Moreover, its capacity to be an ML model trained for general tasks and perform very well in domain-specific situations is impressive. I am a researcher, and its ability to do sentiment analysis (SA) interests me.
SA is a very widespread Natural Language Processing (NLP). It has several applications and thus can be used in several domains (e.g., finance, entertainment, psychology). However, some fields adopt specific terms and jargon (e.g., finance). Hence, whether general domain ML models can be as capable as domain-specific models is still an open research question in NLP.
If you ask the ChatGPT this research question — which is this article’s title — it will give you a humble answer (go on, try it). But, oh, my dear reader, I usually wouldn’t spoil this for you, but you have no idea how surprisingly modest this ChatGPT answer was…
Still, as an AI researcher, industry professional, and hobbyist, I am used to fine-tuning general domain NLP machine learning tools (e.g., GloVe) for usage in domain-specific tasks. This is the case because it was uncommon for most domains to find an out-of-the-box solution that could do well enough without some fine-tuning. I will show you how this could no longer be the case.
In this text, I compare ChatGPT to a domain-specific ML model by discussing the following topics:
- SemEval 2017 Task 5 — A domain-specific challenge
- Using ChatGPT API to label a dataset with code examples
- Verdict and results of the comparison with reproducibility details
- Conclusion and Results Discussion
- BONUS: How this comparison can be done in an applied scenario
Note 1: This is just a simple hands-on experiment that sheds some light on the subject, NOT an exhaustive scientific investigation.
Note 2: All images unless otherwise noted are by the author.
1. SemEval 2017 Task 5 — A domain-specific challenge
SemEval (Semantic Evaluation) is a renowned NLP workshop where research teams compete scientifically in sentiment analysis, text similarity, and question-answering tasks. The organizers provide textual data and gold-standard datasets created by annotators (domain specialists) and linguists to evaluate state-of-the-art solutions for each task.
In particular, SemEval’s Task 5 of the 2017 edition asked researchers to score financial microblogs and news headlines for sentiment analysis on a -1 (most negative) to 1 (most positive) scale. We’ll use the gold-standard dataset from that year’s SemEval to test ChatGPT’s performance in a domain-specific task. Subtask 2 dataset (news headlines) had two sets of sentences (maximum of 30 words each): the training (1,142 sentences) and the testing (491 sentences) sets.
Considering these sets, the data distribution of sentiment scores and text sentences is displayed below. The plot below shows bimodal distributions in both training and testing sets. Moreover, the graph indicates more positive than negative sentences in the dataset. This will be a piece of handy information in the evaluation section.
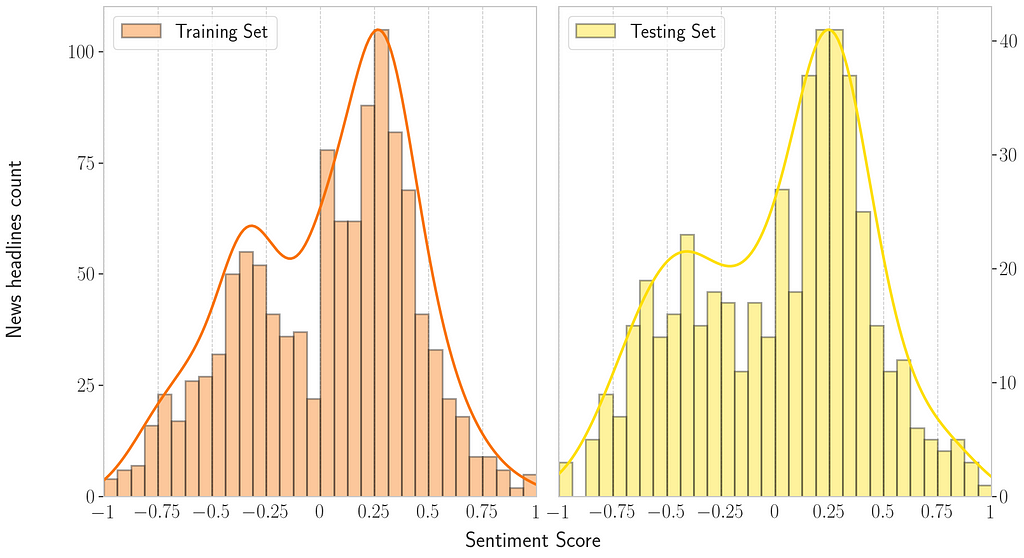
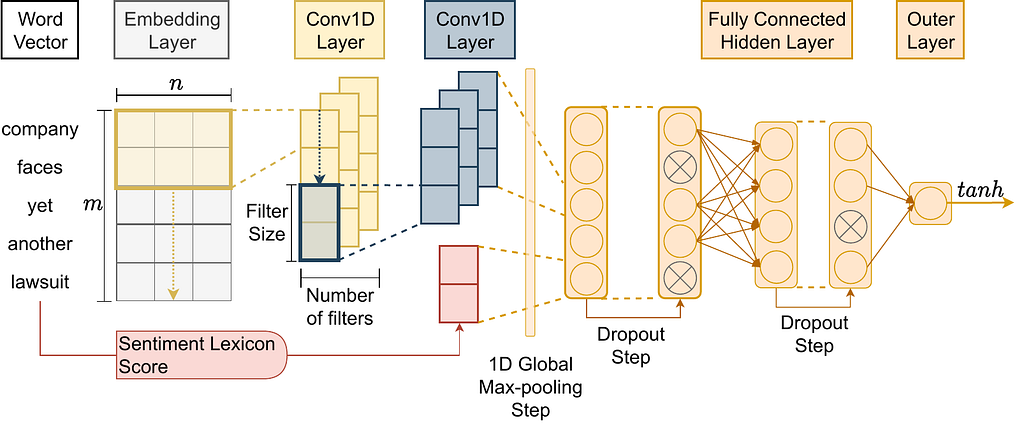
For this subtask, the winning research team (i.e., which ranked best on the test set) named their ML architecture Fortia-FBK. Inspired by this competition’s discoveries, some colleagues and I made a research article (Assessing Regression-Based Sentiment Analysis Techniques in Financial Texts) where we implemented our version of Fortia-FBK and evaluated ways to improve this architecture.
Also, we investigated the factors that made this architecture the winning one. Thus, our implementation (code is here) of this winning architecture (i.e., Fortia-FBK) will be used for comparison with ChatGPT. The architecture (CNN+GloVe+Vader) employed is the one shown below.
2. Using ChatGPT API to label a dataset
Using ChatGPT API has already been discussed here on Medium for synthesizing data. Also, you can find sentiment labeling examples in the ChatGPT API code samples section (Notice that using the API is not free). For this code example, consider SemEval’s 2017 Task gold-standard dataset that you can get here.
Then, to use the API for labeling several sentences at once, use a code as such, where I prepare a full prompt with sentences from a dataframe with the Gold-Standard dataset with the sentence to be labeled and the target company to which the sentiment refers.
def prepare_long_prompt(df):
initial_txt = "Classify the sentiment in these sentences between brackets regarding only the company specified in double-quotes. The response should be in one line with format company name in normal case followed by upper cased sentiment category in sequence separated by a semicolon:\n\n"
prompt = "\"" + df['company'] + "\"" + " [" + df['title'] + ")]"
return initial_txt + '\n'.join(prompt.tolist())
Then, call the API for the text-davinci-003 engine (GPT-3 version). Here I made some adjustments to the code to account for the max number of total characters in the prompt plus the answer, which must be at most 4097 characters.
def call_chatgpt_api(prompt):
# getting the maxium amount of tokens allowed to the response, based on the
# api Max of 4097, and considering the length of the prompt text
prompt_length = len(prompt)
max_tokens = 4097 - prompt_length
# this rule of dividing by 10 is just a empirical estimation and is not a precise rule
if max_tokens < (prompt_length / 10):
raise ValueError(f'Max allowed token for response is dangerously low {max_tokens} and might not be enough, try reducing the prompt size')
response = openai.Completion.create(
model="text-davinci-003",
prompt=prompt,
temperature=0,
max_tokens=max_tokens,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
return response.choices[0]['text']
long_prompt = prepare_long_prompt(df)
call_chatgpt_api(long_prompt)
Ultimately, doing that for a total of 1633 (training + testing sets) sentences in the gold-standard dataset and you get the following results with ChatGPT API labels.

2.1. Issues with ChatGPT and its API at scale
As with any other API, there are some typical requirements
- Requests rate limit that requires throttling adjustments
- Request limit of 25000 tokens (i.e., sub-word unit or a byte-pair encoding)
- Maximum length of 4096 tokens per request (prompt + response included)
- Cost of $0.0200 / 1K tokens (Note: I never spent more than U$ 2 after everything I did)
However, these are just the typical requirements when dealing with most APIs. Moreover, remember that in this domain-specific problem, there is a target entity (i.e., company) for each sentence for the sentiment. So I had to play around until I designed a prompt pattern that made it possible to label the sentiment of several sentences at once and make it easy to process the results afterward. Furthermore, that are other limitations that impacted the prompt and code that I showed previously. Specifically, I found issues using this text API for several sentences (>1000).
- Reproducibility: ChatGPT’s sentiment assessments on sentiment can change significantly with very few changes to the prompt (e..g, adding or removing a comma or a dot of the sentence).
- Consistency: If you do not clearly specify the pattern response, ChatGPT will get creative (even if you select a very low randomness parameter), making it hard to process results. Moreover, even when you specify the pattern, it can output inconsistent output formats.
- Mismatches: Even though it can very precisely identify the target entity (e.g., company) you want to have the sentiment assessed in a sentence, it can mix up results when doing this at scale. For example, suppose you pass on 10 sentences each with a target company. Still, some of the companies appear in other sentences or are repeated. In that case, ChatGPT can mismatch the targets and sentence sentiments, change the order of the sentiment labels or provide fewer than 10 labels.
- Bias: Currently, the issue of ChatGPT bias is well known. And there are ideas on how to improve this problem. However, until then, beware that you are learning to use a Biased API.
All of these issues imply a learning curve to properly use the (biased) API. It required some fine-tuning to get what I needed. Sometimes I had to do many trials until I reached the desired outcome with minimal consistency.
You should send as many sentences as possible at once in an ideal situation for two reasons. First, you want to get your labels as fast as possible. Second, the prompt counts as tokens in the cost, so fewer requests mean less cost. Yet, we have a limit of 4096 tokens per request. Also, given the issues I mentioned, another notable API limitation exists. Passing too many sentences at once increases the chance of mismatches and inconsistencies. Thus, it is up to you to keep increasing and decreasing the number of sentences until you find your sweet spot for consistency and cost. If you do not do that properly, you will suffer in the post-processing results phase.
In summary, if you have thousands of sentences to process, start with a batch of a few half-dozen sentences and no more than 10 prompts to check on the reliability of the responses. Then, slowly increase the number to verify capacity and quality until you find the optimal prompt and rate that fits your task.
3. Verdict and results of the comparison
3.1. Details of the comparison
ChatGPT, in its GPT-3 version, cannot attribute sentiment to text sentences using numeric values (no matter how much I tried). However, specialists attributed numeric scores to sentence sentiments in this particular Gold-Standard dataset.
So, to make a viable comparison, I had to:
- Categorize the dataset scores into Positive, Neutral, or Negative labels.
- Do the same to the scores produced from the domain-specific ML model.
- Define a range of possible thresholds (with steps of 0.001) for determining where one category begins and ends. Then, given the threshold TH, scores above +TH are considered Positive sentiment, below -TH is Negative, and between are Neutral.
- Iterate over the range of thresholds and evaluate both models’ accuracy at each point.
- Investigate their performance by sets (i.e., training or testing), given that the domain-specific model would have an unfair advantage in the training set.
The code for step 3 is below. And the complete code for replicating the whole comparison is here.
def get_df_plot(df, th_sequence):
temp_list = []
for th in th_sequence:
converted_gold_arr = np.where((df['sentiment'] <= th) & (df['sentiment'] >= -th), 0, np.sign(df['sentiment']))
converted_model_arr = np.where((df['cnn-pred-sent'] <= th) & (df['cnn-pred-sent'] >= -th), 0, np.sign(df['cnn-pred-sent']))
df['sent_cat_value'] = converted_gold_arr.astype(np.int64)
df['cnn_pred_sent_cat_value'] = converted_model_arr.astype(np.int64)
corr_gold_chatgpt = df['chatgpt_sent_value'].corr(df['sent_cat_value'])
corr_gold_cnn = df['chatgpt_sent_value'].corr(df['cnn_pred_sent_cat_value'])
acc_gold_chatgpt = (df['chatgpt_sent_value']==df['sent_cat_value']).mean()
acc_gold_cnn = (df['chatgpt_sent_value']==df['cnn_pred_sent_cat_value']).mean()
temp_list.append([th, corr_gold_chatgpt, corr_gold_cnn, acc_gold_chatgpt, acc_gold_cnn])
return pd.DataFrame(data=temp_list, columns=['th', 'corr_gold_chatgpt', 'corr_gold_cnn', 'acc_gold_chatgpt', 'acc_gold_cnn'])
th_sequence = np.arange(0, 1.000001, 0.001)
df_plot = get_df_plot(df.copy(), th_sequence)
3.2. Verdict: Yes, ChatGPT can not only win but shatter the competition
The final result is displayed in the plot below, which shows how the accuracy (y-axis) changes for both models when categorizing the numeric Gold-Standard dataset, as the threshold (x-axis) is adjusted. Also, the training and testing sets are on the left and right sides, respectively.
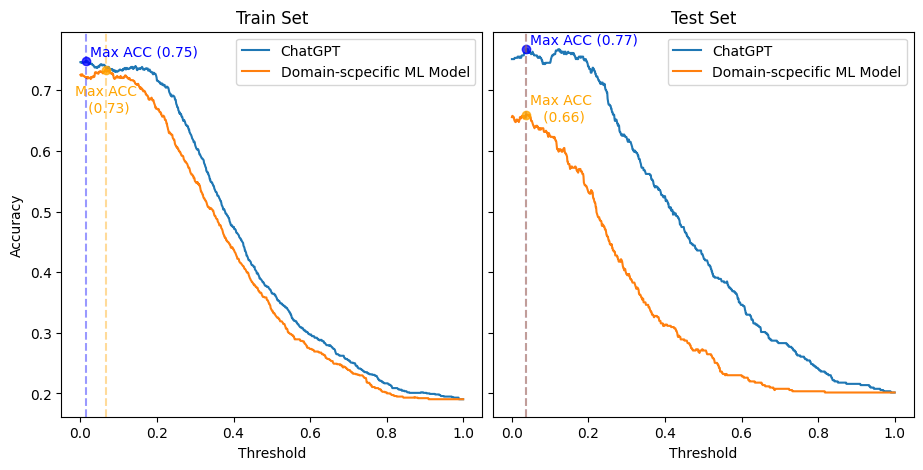
First, I must be honest. I was not expecting this smashing result. Consequently, to not be unfair with ChatGPT, I replicated the original SemEval 2017 competition setup, where the Domain-Specific ML model would be built with the training set. Then the actual ranking and comparison would only occur over the test set.
However, even in the training set, with the most favorable scenario — threshold of 0.066 vs. 0.014 for ChatGPT — the Domain-Specific ML model achieved at most an accuracy 2pp worse than ChatGPT’s best accuracy (0.73 vs. 0.75). Moreover, ChatGPT showed a superior accuracy across all thresholds than the Domain-Specific model in both training and testing sets.
Interestingly, the best threshold for both models (0.038 and 0.037) was close in the test set. And at this threshold, ChatGPT achieved an 11pp better accuracy than the Domain-Specific model (0.66 vs. 077). Also, ChatGPT showed a much better consistency across threshold changes than the Domain-Specific Model. Thus, it is visible that ChatGPT’s accuracy decreased much less steeply.
In resume, ChatGPT vastly outperformed the Domain-Specific ML model in accuracy. Also, the idea is that ChatGPT could be fine-tuned to specific tasks. Hence, imagine how much better ChatGPT could become.
3.3. Investigating ChatGPT sentiment labeling
I always intended to do a more micro investigation by taking examples where ChatGPT was inaccurate and comparing it to the Domain-Specific Model. However, as ChatGPT went much better than anticipated, I moved on to investigate only the cases where it missed the correct sentiment.
Initially, I performed a similar evaluation as before, but now using the complete Gold-Standard dataset at once. Next, I selected the threshold (0.016) for converting the Gold-Standard numeric values into the Positive, Neutral, and Negative labels that incurred ChatGPT’s best accuracy (0.75). Then, I made a confusion matrix. The plots are below.
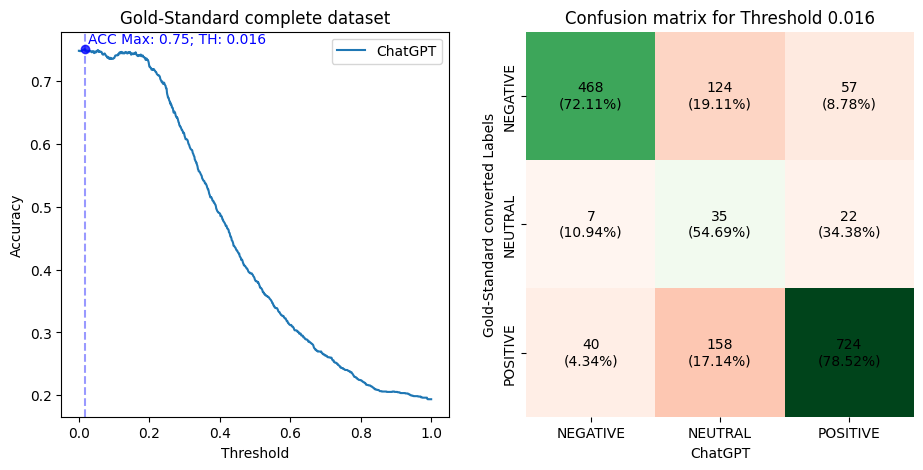
Recall that I showed a distribution of data sentences with more positive scores than negative sentences in a previous section. Here in the confusion matrix, observe that considering the threshold of 0.016, there are 922 (56.39%) positive sentences, 649 (39.69%) negative, and 64 (3.91%) neutral.
Also, notice that ChatGPT is less accurate with neutral labels. This is expected, as these are the labels that are more prone to be affected by the limits of the threshold. Interestingly, ChatGPT tended to categorize most of these neutral sentences as positive. However, since fewer sentences are considered neutral, this phenomenon may be related to greater positive sentiment scores in the dataset.
On the other hand, when considering the other labels, ChatGPT showed the capacity to identify correctly 6pp more positive categories than negative (78.52% vs. 72.11%). In this case, I am not sure this is related to each score spectrum’s number of sentences. First, because there are much more sentences of each category type. Second, observe the number of ChatGPT’s misses that went to labels in the opposite direction (positive to negative or vice-versa). Again, ChatGPT makes more such mistakes with the negative category, which is much less numerous. Thus, ChatGPT seems more troubled with negative sentences than with positive ones.
3.4. Some specific cases and comparison to Human Specialists
I selected a few sentences with the most noticeable particularities between the Gold-Standard (human scores) and ChatGPT. Then, I used the same threshold established previously to convert the numerical scores into sentiment labels (0.016). Moreover, ChatGPT has already been reported to outperform humans. Thus, I investigated the discrepancies and gave my ruling, to which either Humans or the Chatgpt I found was more precise.
Also, since at least 2018, the American agency DARPA has delved into the significance of bringing explainability to AI decisions. Outstandingly, ChatPGT presents such a capacity: it can explain its decisions. This capability helped me to give my ruling. The table below displays this examination.
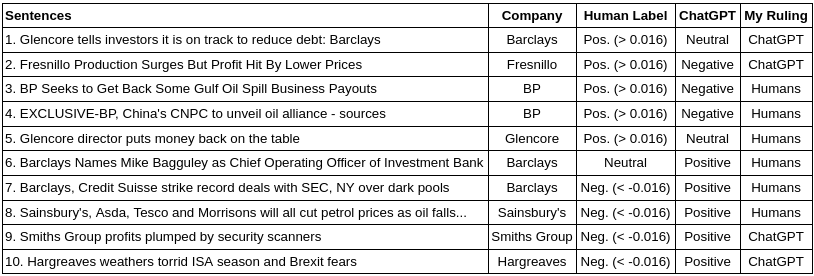
Starting with the cases where I ruled in favor of human specialists. In the cases of sentences 3 and 4, ChatGPT should have realized that getting back payouts and company alliances are generally considered beneficial in the finance domain. However, in the case of sentence 7, I asked it to explain its decision, and here is what ChatGPT replied:
The positive sentiment towards Barclays is conveyed by the word “record,” which implies a significant accomplishment for the company in successfully resolving legal issues with regulatory bodies.
In the case of this sentence, ChatGPT did not comprehend that, although striking a record deal may generally be good, the SEC is a regulatory body. Hence, striking a record deal with the SEC means that Barclays and Credit Suisse had to pay a record value in fines.
Moving on to sentences 5 and 8, these were very tough calls. Let me be clear, humans were correct in their assessments. However, it is just the case that ChatGPT just couldn’t have guessed those ones. In sentence 5, it required knowledge of the situation at that moment in time to understand that the sentence represented a good outcome. And for sentence 8, knowledge is needed that an oil price drop correlates to a stock price drop for that specific target company.
Then, for sentence 6, the most neutral a sentence can get with a zero sentiment score, ChatGPT explained its decision as follows:
The sentence is positive as it is announcing the appointment of a new Chief Operating Officer of Investment Bank, which is a good news for the company.
However, this was a generic and not very insightful response and did not justify why ChatGPT thinks the appointment of this particular executive was good. Thus, I agreed with the human specialists in this case.
Interestingly, I ruled favorably in sentences 1, 2, 9, and 10 for ChatGPT. Moreover, looking carefully, human specialists should have paid more attention to the target company or the overall message. This is particularly emblematic in sentence 1, where specialists should have recognized that although the sentiment was positive for Glencore, the target company was Barclays, which just wrote the report. In this sense, ChatGPT did better discerning the sentiment target and meaning in these sentences.
4. Conclusion and Results Discussion
As seen in the table below, achieving such a performance required lots of financial and human resources.
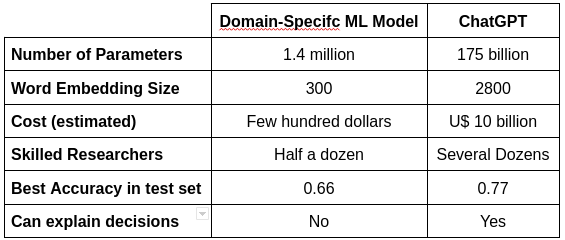
In this sense, even though ChatGPT outperformed the domain-specific model, the ultimate comparison would need fine-tuning ChatGPT for a domain-specific task. Doing so would help address if the gains in performance of fine-tuning outweigh the effort costs.
Furthermore, one of the most essential factors in a textual model is the size of the word embeddings. This technology has evolved since the SemEval 2017 edition. Thus, some updates in this part could significantly increase the results of the domain-specific model.
On another note, with the popularity of generative text models and LLMs, some open-source versions could help assemble an interesting future comparison. Moreover, the capacity of LLMs such as ChatGPT to explain their decisions is an outstanding, arguably unexpected accomplishment that can revolutionize the field.
5. BONUS: How this comparison can be done in an applied scenario
Sentiment analysis in different domains is a stand-alone scientific endeavor on its own. Still, applying the results of sentiment analysis in an appropriate scenario can be another scientific problem. Also, as we are considering sentences from the financial domain, it would be convenient to experiment with adding sentiment features to an applied intelligent system. This is precisely what some researchers have been doing, and I am experimenting with that, also.
In 2021 I and some colleagues published a research article on how to employ sentiment analysis on a applied scenario. In this article — presented at the Second ACM International Conference on AI in Finance (ICAIF’21) — we proposed an efficient way to incorporate market sentiment into a reinforcement learning architecture. The source code for the implementation of this architecture is available here, and a part of it’s overall design is displayed below.
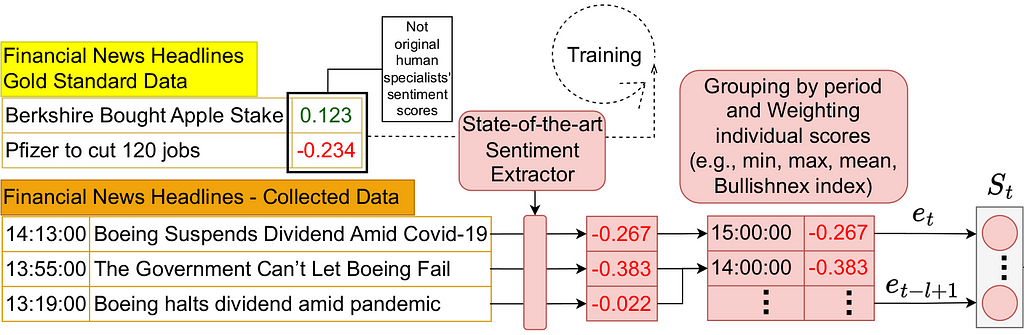
This architecture was designed to work with numerical sentiment scores like those in the Gold-Standard dataset. Still, there are techniques (e.g., Bullishnex index) for converting categorical sentiment, as generated by ChatGPT in appropriate numerical values. Applying such a conversion makes it possible to use ChatGPT-labeled sentiment in such an architecture. Moreover, this is an example of what you can do in such a situation and is what I intend to do in a future analysis.
5.1. Other articles in my line of research (NLP, RL)
- Lima Paiva, F. C.; Felizardo, L. K.; Bianchi, R. A. d. C. B.; Costa, A. H. R. Intelligent Trading Systems: A Sentiment-Aware Reinforcement Learning Approach. Proceedings of the Second ACM International Conference on AI in Finance (ICAIF ‘21).
- Felizardo, L. K.; Lima Paiva, F. C.; de Vita Graves, C.; Matsumoto, E. Y.; Costa, A. H. R.; Del-Moral-Hernandez, E.; Brandimarte, P. Outperforming algorithmic trading reinforcement learning systems: A supervised approach to the cryptocurrency market. Expert Systems with Applications (2022), v. 202, p. 117259.
- Felizardo, L. K.; Lima Paiva, F. C.; Costa, A. H. R.; Del-Moral-Hernandez, E. Reinforcement Learning Applied to Trading Systems: A Survey. arXiv, 2022.
Resources Used Here
- Comparison Jupyter notebook
- Domain-specific machine learning model
- Gold-Standard Dataset
- Code for applied sentiment analsyis scenario (ITS-SentARL)
Main References
- Khadjeh Nassirtoussi, A., Aghabozorgi, S., Ying Wah, T., and Ngo, D. C. L. Text mining for market prediction: A systematic review. Expert Systems with Applications (2014), 41(16):7653–7670.
- Loughran, T. and Mcdonald, B. When Is a Liability Not a Liability ? Textual Analysis , Dictionaries , and 10-Ks. Journal of Finance (2011), 66(1):35–65.
- Hamilton, W. L., Clark, K., Leskovec, J., and Jurafsky, D. Inducing domain-specific sentiment lexicons from unlabeled corpora. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 595–605.
- Cortis, K.; Freitas, A.; Daudert, T.; Huerlimann, M.; Zarrouk, M.; Handschuh, S.; Davis, B. SemEval-2017 Task 5: Fine-Grained Sentiment Analysis on Financial Microblogs and News. Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017).
- Davis, B., Cortis, K., Vasiliu, L., Koumpis, A., Mcdermott, R., and Handschuh, S. Social Sentiment Indices Powered by X-Scores. ALLDATA, The Second Inter-national Conference on Big Data, Small Data, Linked Data and Open Data (2016).
- Ferreira, Taynan; Lima Paiva, F. C.; Silva, Roberto da; Paula, Angel de; Costa, Anna; Cugnasca, Carlos. Assessing Regression-Based Sentiment Analysis Techniques in Financial Texts. 16th National Meeting on Artificial and Computational Intelligence (ENIAC), 2019.
Reaching Out
Can ChatGPT compete with domain-specific sentiment analysis Machine Learning Models? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
...