

 800+ IT
News
als RSS Feed abonnieren
800+ IT
News
als RSS Feed abonnieren📚 How to Identify Fuzzy Duplicates in Your Tabular Dataset
💡 Newskategorie: AI Nachrichten
🔗 Quelle: towardsdatascience.com
Effortless data deduplication at scale.

In today’s data-driven world, the importance of high-quality data to build quality systems cannot be overstated.
The availability of reliable data is highly critical for teams to make informed decisions, develop effective strategies, and gain valuable insights.
However, at times, the quality of this data gets compromised by various factors, one of which is the presence of fuzzy duplicates.
A set of records are fuzzy duplicates when they look similar but are not 100% identical.
For instance, consider the two records:

In this example, the two records have similar but not identical values for both the name and address fields.
How do we get duplicates?
Duplicates can arise due to various reasons, such as misspellings, abbreviations, variations in formatting, or data entry errors.
These, at times, can be challenging to identify and address, as they may not be immediately apparent. Thus, they may require sophisticated algorithms and techniques to detect.
Implications of duplicates
Fuzzy duplicates can pose significant implications on data quality. This is because they result in inaccurate or incomplete analysis and decision-making.
For instance, if your dataset contains fuzzy duplicates, and you analyze it, you may end up overestimating or underestimating certain variables. This will lead to flawed conclusions.
Having understood the importance of the problem, in this blog post, let’s understand how you can perform data deduplication.
Let’s begin 🚀!
The Naive Approach
Imagine you have a dataset with over a million records that may contain some fuzzy duplicates.
The simplest yet intuitive approach that many often come up with involves comparing every pair of records.
However, this quickly gets infeasible as the size of your dataset grows.
For instance, if you have a million records (10⁶), by following the naive approach, you would have to perform over 10¹² comparisons (n²), as shown below:
def is_duplicate(record1, record2):
## function to determine whether record1 and record2
## are similar or not.
...
for record1 in all_records:
for record2 in all_records:
result = is_duplicate(record1, record2)
Even if we assume a decent speed of 10,000 comparisons per second, it will take roughly three years to complete.
CSVDedupe
CSVDedupe is an ML-based open-source command-line tool that identifies and removes duplicate records in a CSV file.
One of its key features is blocking, which drastically improves the run-time of deduplication.
For instance, if you are finding duplicates in names, the approach suggests that comparing the name “Daniel” to “Philip” or “Shannon” to “Julia” makes no sense. They are guaranteed to be distinct records.
In other words, two duplicates will always have some common lexical overlap. However, the naive approach still compares them.
Using blocking, CSVDedupe groups records into smaller buckets and only performs comparisons between them.
This is an efficient way to reduce the number of redundant comparisons, as it is unlikely that records in different groups will be duplicates.
For example, one grouping rule could be to check if the first three letters of the name field are the same.
In that case, records with different first three letters in their name field would be in different groups and would not be compared.
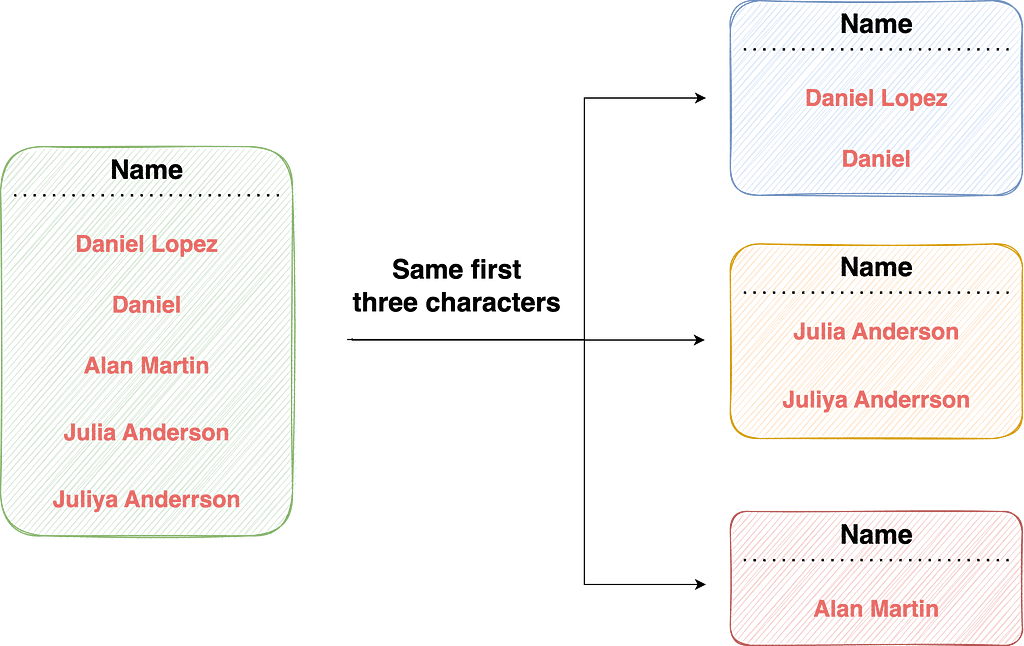
However, records with the same first three letters in their name field would be in the same block, and only those records would be compared to each other.
This saves us from many redundant comparisons, which are guaranteed to be non-duplicates, like “John” and “Peter.”
CSVDedupe uses active learning to identify these blocking rules.
Let’s now look at a demo of CSVDedupe.
Install Dedupe
To install CSVDedupe, run the following command:
https://medium.com/media/a16d80af1edf8e4e0c289dad54fa8711/hrefAnd done! We can now move to experimentation.
Dummy data
For this experiment, I have created dummy data of potential duplicates. This is shown below:
https://medium.com/media/6431df057c8a39a0294d7ce3d304b647/hrefAs you can predict, the fuzzy duplicates are (0,1), (2,3), and (6,7).
CSVDedupe is used as a command-line tool. Thus, we should dump this data into a CSV file.
https://medium.com/media/86c80c818ac4732ced18b2860b2d9883/hrefMarking duplicates
In the command line, CSVDedupe takes an input CSV file and a couple more arguments.
The command is written below:
https://medium.com/media/fdc762751d72aa869ccd413fa19d256f/hrefFirst, we provide the input CSV file. Next, we specify the fields we wish to consider for deduplication. This is specified as --field_names. In this case, we wish to consider all fields for deduplication, but if you want to mark duplicates based on a subset of column entries, you can do it with this argument.
Lastly, we have the --output_file argument, which, as the name suggests, is used to specify the name of the output file.
When we run this in the command line, CSVDedupe will perform its active learning step.
In a gist, it will pick some instances from the given data and ask you if they are duplicates or not, as shown below:

You should provide your input as long as you wish to. Once you are done, press f.
Next, it will automatically start identifying duplicates based on the blocking predicates learned by CSVDedupe during its active learning.
Once done, the output will be stored in the file provided, specified in the --output_file argument.
Post deduplication, we get the following output:
https://medium.com/media/0a5d7e1a8036372997ce9bc63449d7a1/hrefCSVDedupe inserts a new column, namely Cluster ID. A set of records with the same Cluster ID refers to potentially duplicated records, as identified by the CSVDedupe’s model.
For instance, in this case, the model suggests that both records under Cluster ID = 0 are duplicates, which is also correct.
https://medium.com/media/b640eb5c953bcce1048796a08ccb2164/hrefConclusion
With this, we come to the end of this blog.
To conclude, duplicates can be extremely concerning in a dataset as they can lead us to draw wrong conclusions from data.
While the naive approach is a perfect solution when records are fewer, it quickly gets infeasible with scale.
CSVDedupe provides an elegant and clever solution to data deduplication by reducing the number of comparisons with blocking.
What’s more, using its substitute, dedupe, you can also perform data deduplication in Python.
Thanks for reading!
Found this blog interesting?
If you want to learn more such elegant tips and tricks about Data Science and Python, I post an informative tip daily on LinkedIn.
You can find all the tips I have posted in My LinkedIn Post Archive. You can follow me on LinkedIn to see all future posts.
Alternatively, you can also receive them via email by subscribing below:
How to Identify Fuzzy Duplicates in Your Tabular Dataset was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
...