

 800+ IT
News
als RSS Feed abonnieren
800+ IT
News
als RSS Feed abonnieren📚 GPT-4, 128K context - it is not big enough
💡 Newskategorie: Programmierung
🔗 Quelle: dev.to
OpenAI has recently introduced the GPT-4 Turbo model with a 128K context window. A 4x boost to the previous maximum of 32K in GPT-4.
Did you know that this context size is enough to hold 1684 tweets or 123 StackOverflow questions? Or that the largest source file from the Linux kernel would require a context window that is 540 times larger than 128k? Hold on for more comparisons.
I've taken a few artefacts, converted them to a textual representation, counted sizes in tokens, and calсulated how many artefacts can fit into a 128K context window.
Smaller ones:

And larger ones:
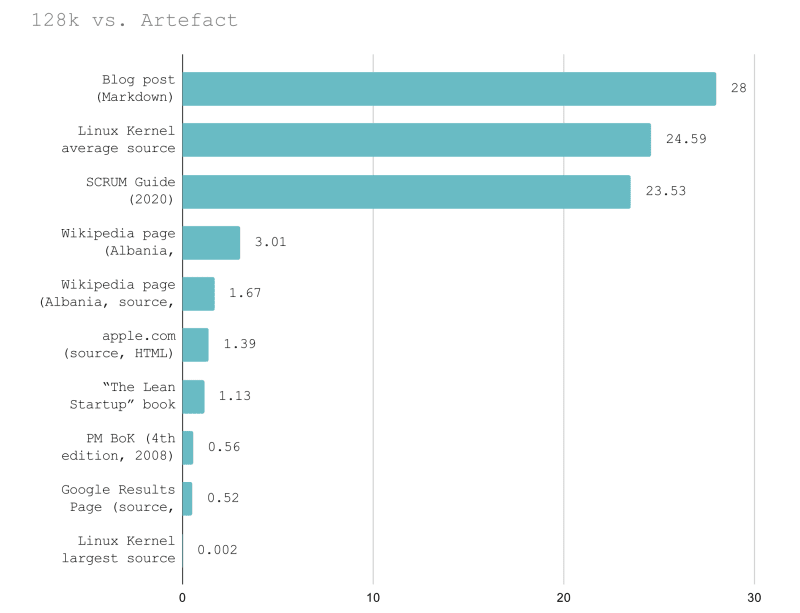
Here's the full table with links/details.
Bottom-line first
Here're some of the conclusions that I argue about further in the post:
- 128k is still not enough for many practical tasks today
- It can barely hold the raw HTML of a single web page OR full contents of all documents that might be required to navigate complex knowledge or draw conclusions
- RAG is a workaround, not a solution, it injects fragments of text that are not enough to navigate complex knowledge bases, maybe out-of-order/unrelated
- You should not expect that 100% of the content window can be effectively used, as you reach 50% the performance degrade
- Huge ramp-up of context windows (10-100x) or Multi-modality may present opportunities for a leap forward
Artefact-to-Text
Large Language Models can only operate on text, as opposed to a new flavour of foundation models - Large Multimodal Models (LMMs).
There're multiple ways a given document/object/entity can be represented as a text. And there's no perfect way to represent all different kinds of digital objects preserving all information.
Converting a document to text can be lossy: you lose styles, structure, media, or even some of the text information.
Take for example this StackOverflow question:

If I select this element in the browser and copy/paste it text editor, it will look like this:

Notice how the vote counter turns into a single number (2), there's no formatting of code blocks, and the URLs for links (dart:typed_data and file) are missing.
The source in Markdown has way more nuances (except the vote counter):

And it makes sense to feed LLMs not with pure text as seen on the screen, but with the source text. LLMs are fine with understanding structured inputs and there're many examples of prompts that operate on XML, HTML, JSON, etc., and provide good results.
With our StackOverflow example, it is just a 10% increase when moving from TXT copy-paste to MD source (947 vs 1037 tokens). However, it is not always possible to have access to the source (in my case as an author I was able to click 'Edit') and one would need to employ certain techniques to extract the text make enrich it with structure and related info.
Though even if we talk of pure text vs source markup, not all languages are as basic and light as Markdown. Take for example web page:
| Artefact | Tokens | Diff, times larger |
|---|---|---|
| Google Results Page (copy/paste, txt) | 975 | |
| Google Results Page (source, HTML) | 246781 | 253x |
| apple.com(copy/paste, txt) | 997 | |
| apple.com(source, HTML) | 92091 | 92x |
| Wikipedia page (Albania, copy/paste, txt) | 42492 | |
| Wikipedia page (Albania, source, wikitext) | 76462 | 1.8x |
If we speak of HTML, we're talking of 10x and even 100x order of magnitude. A significant part of this increase is due to JavaScript and CSS, nevertheless, LLMs even with the largest context window wouldn't be able to operate on raw HTML inputs.
RAG and AI agents
Here's how a Google results page used for counting tokens looks like:

It has 10 results (as long as you don't scroll down and get more results loaded). 131 pages like this will completely fit into a 128K context window when represented at copy/pasted text (losing styles, links, layouts, interactivity). The same page won't fit into the context when viewed as source HTML (52% of it will fit).
Assume you are building a retrieval-augmented AI agent (the one that can request external sources and have pieces of relevant info injected into the prompt). The agent has tools to make HTTP requests, you are using Chat Completion API from OpenAI, and your model is GPT-4 Turbo with 128k context.
This is called RAG (retrieval augmented generation) and it is typically solved in the following way. The retrieval tool makes an API call, request a page, or reads files. It refines the retrieved data to make the amount of text/tokens smaller to preserve the necessary information. Then it uses a text splitter turning every document into a series of chunks (paragraphs, code blocks, etc.), using certain criteria to make a break (e.g. a new headline in markdown) and making sure each paragraph doesn't exceed a given size (e.g. 1000k tokens). Then each of these text snippets comes through semantic indexing via embedding (gets assigned a vector of a few hundred numbers) and is stored in a vector DB. Then, before a reply to the user is generated, embeddings are used to pick semantically relevant (to the initial user request) text chunks and insert them into the prompt. A few of the key assumptions here are:
- You can efficiently refine the results to smaller texts and keep the required information
- Embeddings can provide relevant pieces of information and restore connections/retrieve related pieces of information

Now assume that we want to operate on arbitrary web pages and have no prior knowledge of web page structure. I.e. you don't have transformers for a given page or can't use CSS/HTML selectors to extract certain info from known parts (i.e. all search results resin in <div> elements with search-result CSS classed). It is the AI agent's job to read HTML, understand the structure of the page, and decide where to move next and which parts to click. Under such assumptions, we can't have an effective refinement of HTML output as long as we don't want a human in the loop. If it is LLM's task to explore the structure of the page and navigate i it, the only option likely to succeed is to give the model the full contents of the page (source HTML). And apparently, even 128K context is not enough for LLM to reliably process pure HTML of an average web page you have on the internet.
And we are not even touching the second part of the problem... What if the knowledge is complex, spread across different documents, have intricate relations... And text splitting and embeddings do not provide a meaningful context for a prompt, you need way more raw inputs. This makes the problem of the context size even more acute.
Multiple-modalities
How can we build the kind of universal AI agent that can crawl any web page, look into it, make assumptions of knowledge structure, and extract relevant data?
In this paper exploring the capabilities of GPT-4V(ision) there's a nice use case with GUI navigation:

"A picture is worth a thousand words" is a perfect demonstration of how hundreds of thousands of tokens (raw HTML) that can't fit into LLM turn into a small actionable piece of info when changing the modality.
Can you effectively use the full size of the context?
Why is there even a limit to the context window in the first place?
First of all, there's a quadratic complexity problem. When doing inference doubling the input prompt (number of tokens in the request) increases the CPU and memory requirements by 4 - 2 times linger requests will take 4 times longer time to complete.
Besides, for the model to be effective in manipulating larger context windows, it must be trained on larger context windows, also requires more compute.
And there're empirical studies and tests by individual developers that draw a grim picture of advertised vs effective context window. The closer you get to the maximum limit of the context the more likely that LLM will start forgetting or missing certain bits of info in the prompt.
One such test of GPT-4 Turbo says that you can expect no degradation in recall performance (the ability of LLM to find some of the info given in the prompt before) only if you do not exceed 71k token length, ~55%.
That is aligned with my observation working with GPT-3.5 and GPT-4 APIs, if you cross the boundary of 50% context length, you start getting more hallucinations and BS.
How the results were gathered?
I have used VSCode and cptX extension. It has a handy feature of counting the number of tokens (using OpenAI's tokenizer Tiktoken) in the currently open document:
The workflow was the following. I either opened the doc and selected a portion of interest in Safari on Preview (on macOS) and pasted it to open the VSCode file OR opened the source of the doc (HTML, MD, wiki text) and also pasted it to the editor and received the number of tokens when I then put to the spreadsheet.
...