

 800+ IT
News
als RSS Feed abonnieren
800+ IT
News
als RSS Feed abonnieren📚 Unlocking the Power of Text Data with LLMs
💡 Newskategorie: AI Nachrichten
🔗 Quelle: towardsdatascience.com
DATA SCIENCE LAB
Learn how to handle text data with LLMs: a step-by-step guide for newbies

Customer reviews, employee surveys, and social media posts can be incredibly powerful in revealing people’s attitudes toward a specific product or service. However, most data analysts do very little with this type of data. Why, you ask? Generating insights from text data is no easy task and can leave even the most experienced data analysts scratching their heads for days.
This is where Large Language Models (LLMs) come to the rescue. They can help carry out tasks such as translation, summarization, sentiment analysis, and much more. But what is an LLM, exactly? To simplify things, you can think of an LLM as a parrot. Just like a parrot repeats what it hears at home, an LLM imitates human language. A key difference is that LLMs have been trained on a huge volume of data — far beyond what a parrot would learn in its cage! This is why LLMs have the ability to generate coherent and contextually relevant text without the occasional nonsense of a parrot. 🦜
In this article, we’ll explore how LLMs work and how they make it easier than ever for data analysts to extract insights from text data. There are multiple LLMs now available via APIs, each with different capabilities and price points. We’ll be using GPT-3 via OpenAI API. At the time of writing, OpenAI charges for API usage based on the number of requests made and the number of tokens generated. The total cost for this tutorial amounted to $0.2.
Time to dig in!
Table of Contents
▹ Step 1: Downloading the Data
▹ Step 2: Reading the Data
▹ Step 3: Data Pre-Processing
▹ Step 3a: Dealing with NaN Values
▹ Step 3b: Transforming Text for GPT-3
▹ Step 3c: Counting Tokens
▹ Step 4: Setting Up an OpenAI Account
▹ Step 5: Working with GPT-3
▹ Step 6: Summarizing the Results
Prerequisites
To follow along in this tutorial, you will need to have the following:
- Working knowledge of Python
- Python 3 environment
- OpenAI API key (see step 4)
Step 1: Downloading the Data
The dataset we’ll use is an industry-wide survey conducted by Kaggle in 2017 aimed at uncovering new trends in machine learning and data science. For this tutorial, we’ll only be using the freeformResponses csv file, which contains open-ended answers to Kaggle’s questions.
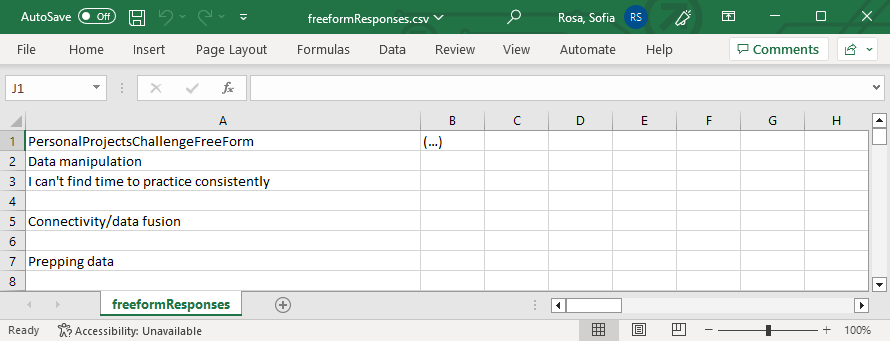
Step 2: Reading the Data
Next, we’ll read the csv file into a dataframe and focus on the column “PersonalProjectsChallengeFreeForm”. This column contains challenges people face when using public datasets for their personal projects. Kaggle, as a platform for data science and machine learning, can use these insights to improve its services (e.g., by developing relevant content, tutorials, and resources that specifically address these challenges).
# load library
import pandas as pd
# read file and create df
df = pd.read_csv('freeformResponses.csv', usecols = ['PersonalProjectsChallengeFreeForm'])
# check output
df.head()

Step 3: Data Pre-Processing
Data pre-processing involves a series of steps to clean and prepare the data for analysis. GPT-3 can handle relatively clean and structured text data without the need for extensive pre-processing. However, for complex or non-standard data, some extra pre-processing may be necessary to ensure the best results when leveraging GPT-3. This is something to keep in mind if your text contains multiple languages, spelling errors, or domain-specific terms.
Step 3a: Dealing with NaN Values
We’ll start by dealing with NaN (Not A Number) values. NaN values represent missing or undefined values with very distinct properties, making it important to detect them early on using the isna() function. Once identified, we can take appropriate measures to handle them effectively.
# count NaN values
df.isna().sum()
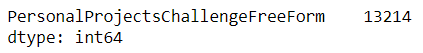
There are 13,214 NaN values (80% of all responses!), meaning that these people did not provide an answer to the question. The simplest approach is to remove all the entries that contain NaN values using the dropna() function. However, depending on your specific use case, you might prefer to handle NaN values differently, such as by replacing them with specific values.
# drop NaN values
df = df.dropna()
# check output
df.head()

For demo purposes, we’ll work with only the first 500 (non-null) responses from the survey.
# select first 500 rows
df = df.head(500)
Step 3b: Transforming Text for GPT-3
Next, we’ll transform the text data into a format suitable for GPT-3. We’ll extract all the values from the “PersonalProjectsChallengeFreeForm” column and store them in the “challenges” list. This transformation begins with the use of the squeeze() function, which converts the dataframe into a pandas series. Subsequently, the tolist() function converts this series into a list.
# convert df into a series and then into a list
challenges = df.squeeze().tolist()
# check output
challenges[:5]

In this example, “challenges” is a list where each element represents a response from the original survey. We’ll provide this text as input to GPT-3.
Step 3c: Counting Tokens
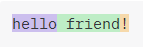
Our text is almost ready for GPT-3. Before we proceed, it’s important that we understand how GPT-3 understands and works with text. Initially, it performs tokenization, which involves splitting the text into smaller units known as tokens. Tokens are units of text, such as sentences, words, numbers, or even punctuation marks. For example, the phrase “hello friend!” can be split into three tokens: “hello”, “ friend” and “!”.
After tokenization, GPT-3 proceeds to encoding, which means it converts these tokens into token numbers. In our example, the three tokens “hello”, “ friend” and “!” can be converted into three token numbers: “15339”, “ 4333” and “0”.
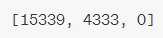
By determining the number of tokens in our text, we’ll know whether the text is too long for the model to process as well as how much an OpenAI API call will cost (as API calls are billed based on the number of tokens sent in your input plus the number of tokens that GPT returns in the output).
To do this, we’ll install a library called tiktoken and import the necessary module encoding_for_model. Since different LLMs use different methods for encoding text, we’ll need to specify the model we’ll be using, which is “gpt-3.5-turbo-16k”. For each sentence, we’ll then tokenize and encode the text.
# install library
pip install tiktoken
# import library
from tiktoken import encoding_for_model
# define the model for encoding text, in this case, "gpt-3.5-turbo-16k"
enc = encoding_for_model("gpt-3.5-turbo-16k")
# create an empty list to store tokens
tokens = []
# loop through each sentence in the 'challenges' list
for sentence in challenges:
# encode the sentence using the specified model and append it to the 'tokens' list
tokens.append(enc.encode(sentence))
# check output
pd.DataFrame(data={'challenges':challenges, 'tokens':tokens}).head(3)

The last step is to count the tokens, which can be accomplished by determining the length of the list “num_tokens”.
# create an empty list to store the number of tokens
num_tokens = []
# iterate through the 'tokens' list, which is a list of lists
for item in tokens:
# nested loop to iterate through sublists within 'tokens'
for subitem in item:
# append the subitem (token) to the 'num_tokens' list
num_tokens.append(subitem)
# check output
len(num_tokens)
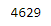
To estimate the total cost based on our input, we can refer to the pricing documentation. In our case, 4629 tokens would translate to a cost of $0.01.
Step 4: Setting Up an OpenAI Account
Our text is finally ready for GPT-3 (we’re getting closer to the good stuff!). To work with GPT-3, we’ll be using the OpenAI API. Make sure that you have an OpenAI account set up to access the OpenAI API. If you don’t already have an account, follow the steps below to create one.
To kick things off, head to the OpenAI website and click on the “Sign Up” button in the top right corner of the page. Fill in the form with your email address, create a password, and provide any other necessary info. Then, hit the “Create Account” button. Keep an eye on your inbox as you’ll receive a confirmation email. Click the link in the email to verify your account. Once that’s done, you’re all set to log in.
With your account created, the next step is funding it. Remember, as you use the API, you’ll be billed for your usage. Simply go to “Manage Account” and find the “Billing” tab. There, you can add your payment card details and specify the initial amount you want to put in your account.
The final important step is to generate your API Key, which serves as a private access key to the API. You can create it in the “API Keys” tab. Keep this key safe because it can’t be recovered if lost. However, if it slips through the cracks, you do have the option to create a new one.
Step 5: Working with GPT-3
Now that we have access to GPT-3 through the OpenAI API, we can send a request containing the input and API key. In return, we’ll get a response containing the GPT-3 output.
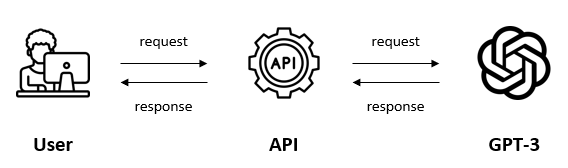
First, we’ll install a library called openai. Then, we’ll set up the API key to authenticate our requests.
# install library
pip install openai
# import library
import openai as ai
# replace 'your_api_key' with your actual API key
ai.api_key = 'your_api_key'
We’ll send our text to GPT-3 and ask it to summarise the main topics, which are then stored in the “response” variable.
💡 Note: This code is a simplified example, and you can adapt it for various tasks by adjusting the user message and system message according to your specific needs.
# get GPT-3 response
response = ai.ChatCompletion.create(
model = 'gpt-3.5-turbo-16k',
messages = [
{"role": "system", "content": "You're a helpful assistant. Your task is to analyze a set of reviews."},
{"role": "user", "content": f'''
Below is a set of reviews. Please, identify the main topics mentioned in these comments.
Return a list of 5 topics with description. Reviews:
{challenges}
'''
}
],
temperature = 0,
max_tokens = 6000
)
Let’s go through the code step by step:
- response = ai.ChatCompletion.create(: This line initiates a request to GPT-3 and assigns the response to the variable “response”.
- model = 'gpt-3.5-turbo-16k': This parameter specifies which GPT-3 model to use.
- messages = [ ... ]: This section defines a list of messages for which GPT-3 will create a response. Each message has a role (e.g., system or user) and content. The system message helps set the behavior of GPT-3. For example, we can say: “You’re a helpful assistant. Your task is to analyze a set of reviews”. The user message, on the other hand, provides instructions for the task. For example, we can say: “Below is a set of reviews. Please, identify the main topics mentioned in these comments”.
- temperature = 0: This parameter influences the randomness of the responses. You can think of it as a way to control how creative and unpredictable the responses are. Setting it to 0 means that you’ll get the same output every time you ask, almost like a broken record. On the other hand, setting it to a higher value (e.g., 0.8) means that you’ll get a fresh output.
- max_tokens = 6000: This parameter specifies the maximum number of tokens the response can contain. Setting it to 6000 ensures that the response doesn't exceed this length. If the response exceeds this limit, it will be truncated.
After receiving a response from GPT-3, we’ll return the content (excluding any additional meta-information).
# show response
response['choices'][0]['message']['content']
GPT-3 returned five topics:
“1. Data cleaning and preparation: Many reviews mention the challenge of cleaning and preparing the data for analysis. This includes dealing with missing values, formatting issues, unstructured data, and the need for data wrangling.
2. Data quality and documentation: Several reviews highlight the poor quality of the data, including lack of documentation, incorrect documentation, and unreliable data. Issues with data completeness, accuracy, and reliability are also mentioned.
3. Finding and accessing relevant datasets: Many reviewers express difficulties in finding the right datasets for their projects. This includes challenges in finding datasets that match specific requirements, lack of availability, limited size or relevance of public datasets, and the need to collect personal data.
4. Connectivity and data fusion: Some reviews mention challenges related to data connectivity and fusion, such as integrating data from different sources, dealing with inconsistent formats, and merging datasets.
5. Computing power and scalability: A few reviews mention challenges related to computing power and scalability, particularly when working with large datasets or when processing data on a single machine.’,
‘These topics reflect common challenges faced by individuals when working with data, including issues related to data quality, data preparation, dataset availability, and technical limitations.”
💡 Note: While GPT-3 is powerful as it is, you can often achieve better results by fine-tuning the model with your training data.
Step 6: Summarizing the Results
These topics reflect common challenges faced by individuals when working with data, including issues related to data preparation, data quality, reliability, and scalability. A company like Kaggle can leverage these insights to develop educational material that specifically addresses these challenges, thereby providing valuable support for their community.
Conclusion
In this article, we’ve explored the significant potential of LLMs in extracting insights from text data. We’ve discussed how LLMs work and how they can be a game-changer for data analysts dealing with text data. You now have the knowledge to apply these concepts to your own text analysis tasks.
I hope you found this article helpful. If you have any questions or thoughts, I’ll be happy to read them in the comments!
Unlocking the Power of Text Data with LLMs was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
...