

 800+ IT
News
als RSS Feed abonnieren
800+ IT
News
als RSS Feed abonnieren📚 The Rise of Vision Transformers
💡 Newskategorie: AI Nachrichten
🔗 Quelle: towardsdatascience.com
Is the era of ResNet coming to an end?

Over the last decade, computer vision has gone from a promising area of research to a cornerstone of the modern technological revolution. Having once turned heads with the accurate classification of small pixelated images, these technologies can now generate high-resolution images like the one above from thin air from nothing but a short description. Such stunning capabilities are currently the domain of immense model sizes, but not all models that affect our everyday lives are large.
Another line of developments in the past decade of computer vision has been the simultaneous gains in performance and parameter efficiency of smaller models, with their compact memory footprints and higher frame rates enabling developments in areas like smartphone photography, augmented reality, and robotics. Pixelwise semantic segmentation and depth estimation, along with detection and tracking of objects and their 3D poses, can now be performed in real time on increasingly large image sizes, helping autonomous vehicles to plan their daily maneuvers through traffic.
This article discusses an important development in backbone selection for these smaller vision architectures. As we will see, there is a new family of models with performance powerful and lightweight enough to warrant a paradigm shift, and allow the perseverant stalwarts of the past era to retire.
The Convolutional Era
Since AlexNet shattered the ImageNet challenge in 2012 and ignited the world of deep learning research, Convolutional Neural Networks (CNNs) have dominated the computer vision landscape. In particular, the ResNet model famously solved the vanishing gradient problem and improved parameter efficiency in 2015 with the introduction of skip (“residual”) connections, subsequently gaining near ubiquitous use as a backbone for various downstream tasks thanks to its strong knowledge transferability, supplanting VGGNet and becoming the most popular backbone architecture of the time.
And there it has largely remained for nearly eight years, an epic lifespan in the rapid-fire world of computer vision research. But now, there are challengers approaching the throne. Following the meteoric rise of transformers in Natural Language Processing (NLP) that started in 2017 with “Attention is All You Need” and grew into the LLM phenomenon seen today, Vision Transformer (ViT) was the first to show in late October 2020 that a pure transformer architecture could achieve state-of-the-art performance in computer vision tasks, although requiring many more training epochs, resources, and data to do so.
It turns out that the design of CNNs gives them inductive biases such as translation equivariance (via weight sharing) and locality (via small filter sizes) that make them inherently effective on the structure of image data. Transformers can learn these biases from scratch with enough training, but this originally meant that transformers were far less data efficient than CNNs. On the other hand, while CNNs come standard with biases that aid their ability to learn and operate on image data, they lack the capability for global dependency modeling across individual layers offered by the self-attention in transformers, and this cannot be learned with any amount of data.
A study titled “Are Transformers More Robust Than CNNs?” found that while the two architectures are equally robust to adversarial attacks when trained with the same augmentation strategies, transformers demonstrated better generalization to out-of-distribution (OOD) samples in comparison to larger ResNet models trained on any strategy, and the ablation studies indicated that the advantage is driven by the self-attention mechanism.
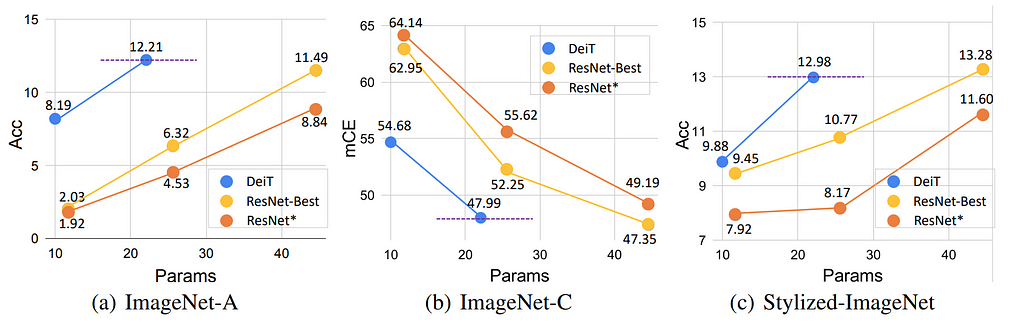
Thus, the attractive qualities of CNNs that make them data efficient when learning image features also seemed to herald their downfall, since their limited receptive fields prevent them from modeling global context, a nontrivial weakness. In the years preceding the ViT publication, several attempts were made to address the long-range dependency issue in CNNs: dilated (aka “atrous”) convolution was explored in models like DeepLab to increase receptive field, Squeeze-and-Excitation, Non-Local Neural Networks, and Attention Augmented Convolutional Neural Networks demonstrate methods to introduce attention into convolutional operations. Bottleneck Transformers (BoTNet) saw notable performance gain at larger image resolutions by replacing the spatial convolution bottleneck blocks in the last 3 layers of ResNet with multi-head self-attention blocks, but larger gains were yet to come.
Vision Transformers
Before transformers could hope to usurp the throne, they also had architectural weaknesses to overcome. The ViT paper was as helpful in demonstrating that a pure transformer architecture could achieve state-of-the-art performance in computer vision tasks as it was in illuminating the challenges posed by this application, including the aforementioned data inefficiency, untenable quadratic complexity of self-attention in relation to image size, and the lack of multi-scale features that are useful in dense prediction tasks like semantic segmentation and monocular depth estimation.
“While these initial results are encouraging, many challenges remain. One is to apply ViT to other computer vision tasks, such as detection and segmentation.”
— Call to action from ViT paper conclusion.
The research community clearly read the 2020 ViT paper like a TODO list, and 2021 was a busy year. First, Data-efficient Image Transformer (DeiT) tackled the data efficiency problem by demonstrating that augmentation methods and knowledge distillation from teacher models were effective in training ViT models well past their previous performance benchmarks in fewer epochs using only the ImageNet dataset, eliminating the need for massive external datasets, and bringing convolution-free vision models into the realm of widespread adoptability. Interestingly, it seemed that using CNNs for the teacher models worked significantly better than the pre-trained DeiTs, possibly because this process teaches their structural biases to the student. Vision transformers were now an official threat to the status quo in terms of data efficiency, but they were still lacking multiscale features.
“Therefore, considering our results, where image transformers are on par with convnets already, we believe that they will rapidly become a method of choice considering their lower memory footprint for a given accuracy.”
— Prophesying from the DeiT paper conclusion.
In late February, a paper titled “Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions” addressed both the lack of multiscale features and self-attention complexity through the use of convolutions. Swin Transformer infuses the structural biases of CNNs, generates multiscale feature maps, and reduces self-attention complexity by attending over shifting local windows, but like PVT, still relies on positional encoding in the patches. Convolutional Vision Transformer (CvT) then changed the game, removing the need for positional encodings by generating overlapping patch embeddings via zero-padded 2D convolution, exploiting a property of CNNs that enables them to encode positional information from zero-padding.
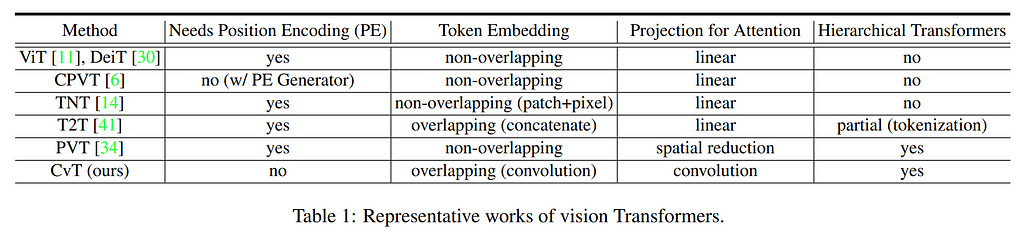
Then, a new version of the PVT (PVTv2) was published simultaneously with Segformer, the latter of which used the former as a backbone to achieve state-of-the-art semantic segmentation performance with impressive parameter efficiency using a lightweight all-MLP decoder. Global-Local Path Network (GLPN) then used this backbone to achieve competitive results in monocular depth estimation (another dense prediction task).
To understand what a breakthrough the PVTv2 really is as a backbone, let’s look at some benchmarks, starting with a chart from the Segformer paper:
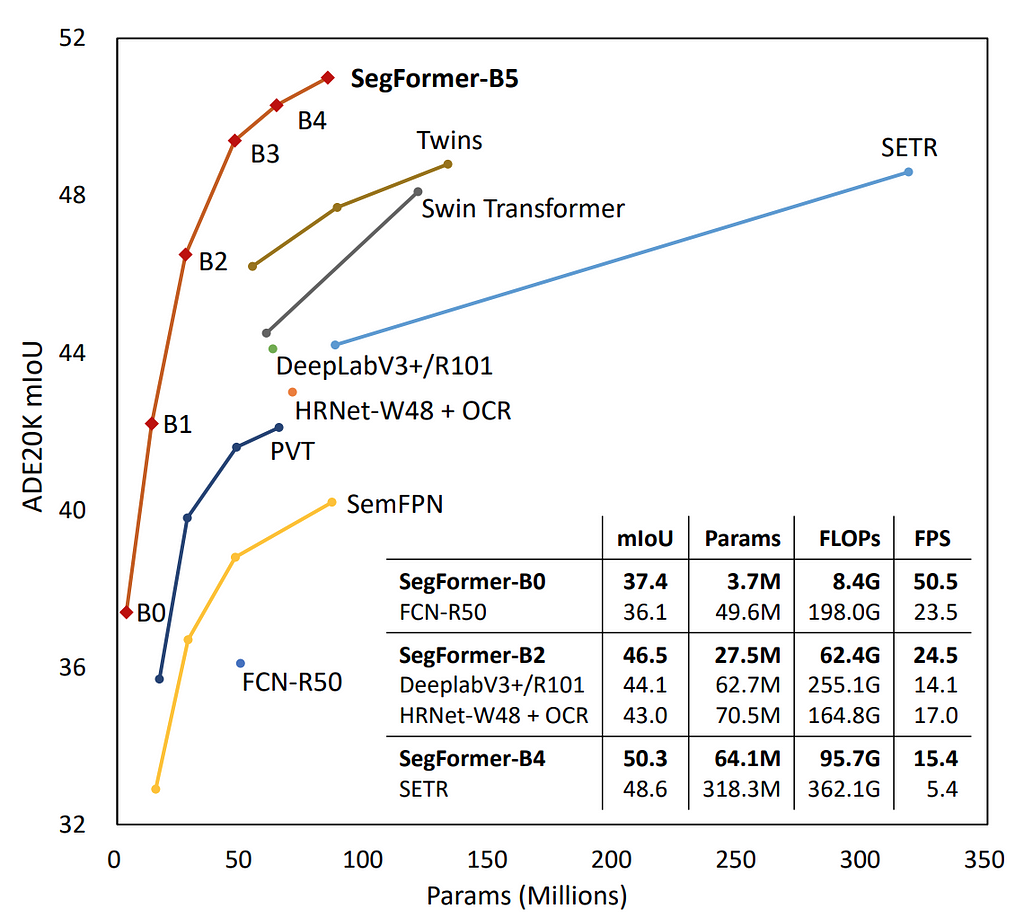
The above graphic clearly shows superior performance and parameter efficiency compared to contemporaneous hierarchical transformers and ResNet-backed architectures (see the Segformer paper for more detailed comparisons).
Next, we can review an example of PVTv2 backing a more complex architecture. Deformable DETR was a strong improvement on the Detection Transformer (DETR), with far more computational and data efficiency thanks to the proposed deformable attention, and trainable in 10x fewer epochs. Panoptic Segformer was a natural extension on top of Deformable DETR for panoptic segmentation that was released later in 2021, and there is one comparison chart from this paper that is particularly informative to our discussion:
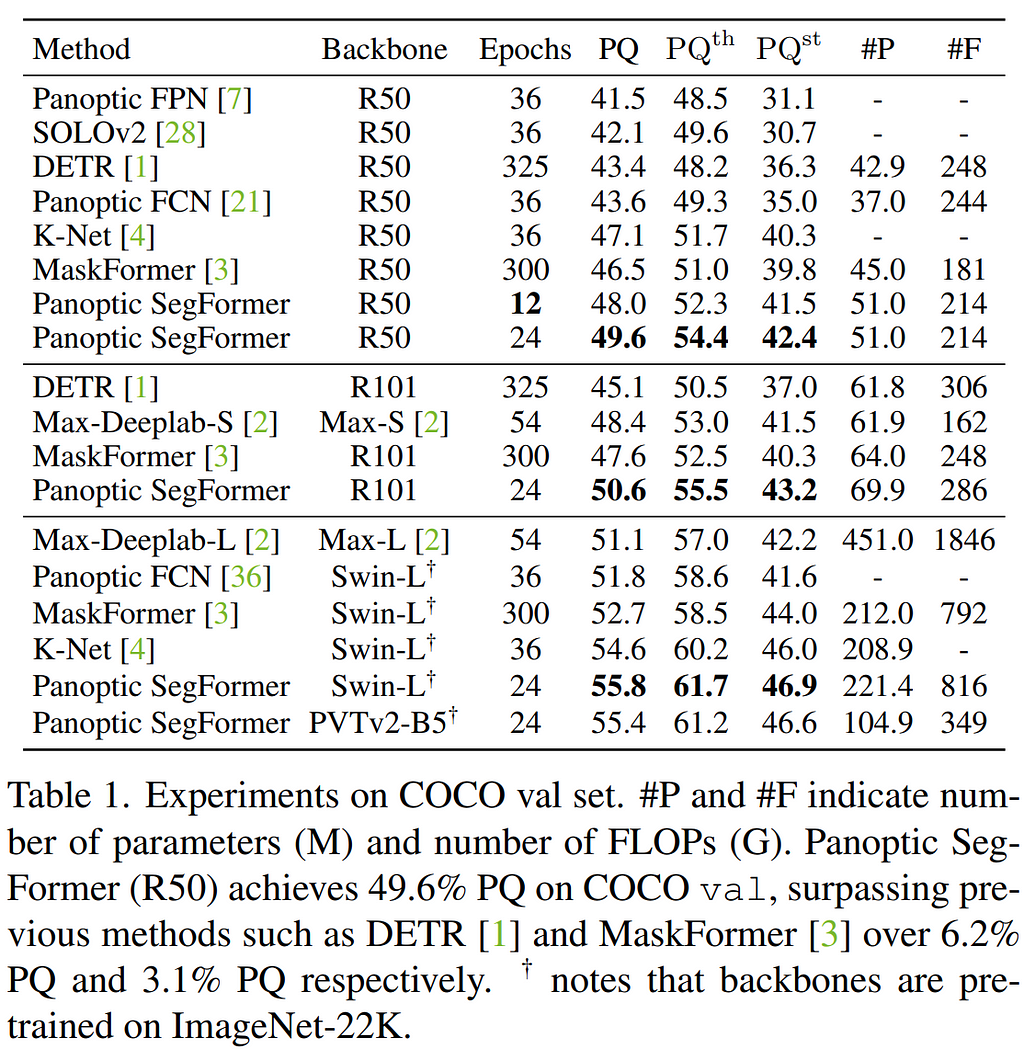
Regrettably, the authors did not benchmark any sizes of PVTv2 backbone other than the largest (B5) version, but we can still glean some important insights from this example. First, we see that although the Swin-L backbone was technically the most performant of the larger models, the PVTv2-B5 had nearly identical performance with less than half the parameters and FLOPS. Further, (although the PVTv2-B3 would be a better comparison) we can see that the PVTv2-B5 is significantly more performant than the ResNet101 backbone.
The success of these models suggests that the Mix Transformer (MiT) encoding layers in the PVTv2 are capable of producing extremely descriptive features with an efficient number of parameters, thanks to adopting a “best of both worlds” approach. By incorporating convolutional operations into transformer layers to make self-attention more efficient, create multiscale features, and infuse inductive biases beneficial to the efficient learning of image data, these hierarchical transformer models may be the next household name in computer vision model development.
The Winner

And so, it appears that the answer is not a fight to the death between CNNs and Transformers (see the many overindulgent eulogies for LSTMs), but rather something a bit more romantic. Not only does the adoption of 2D convolutions in hierarchical transformers like CvT and PVTv2 conveniently create multiscale features, reduce the complexity of self-attention, and simplify architecture by alleviating the need for positional encoding, but these models also employ residual connections, another inherited trait of their progenitors. The complementary strengths of transformers and CNNs have been brought together in viable offspring.
So is the era of ResNet over? It would certainly seem so, although any paper will surely need to include this indefatigable backbone for comparison for some time to come. It is important to remember, however, that there are no losers here, just a new generation of powerful and transferable feature extractors for all to enjoy, if they know where to look. Parameter efficient models like PVTv2 democratize research of more complex architectures by offering powerful feature extraction with a small memory footprint, and deserve to be added to the list of standard backbones for benchmarking new architectures.
Future Work
This article has focused on how the cross-pollination of convolutional operations and self-attention has given us the evolution of hierarchical feature transformers. These models have shown dominant performance and parameter efficiency at small scales, making them ideal feature extraction backbones (especially in parameter-constrained environments). However, there is a lack of exploration into whether the efficiencies and inductive biases that these models capitalize on at smaller scales can transfer to large-scale success and threaten the dominance of pure ViTs at much higher parameter counts.
Large Multimodal Models (LMMS) like Large Language and Visual Assistant (LLaVA) and other applications that require a natural language understanding of visual data rely on Contrastive Language–Image Pretraining (CLIP) embeddings generated from ViT-L features, and therefore inherit the strengths and weaknesses of ViT. If research into scaling hierarchical transformers shows that their benefits, such as multiscale features that enhance fine-grained understanding, enable them to to achieve better or similar performance with greater parameter efficiency than ViT-L, it would have widespread and immediate practical impact on anything using CLIP: LMMs, robotics, assistive technologies, augmented/virtual reality, content moderation, education, research, and many more applications affecting society and industry could be improved and made more efficient, lowering the barrier for development and deployment of these technologies.
The Rise of Vision Transformers was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
...